Kumulativní profil přesnosti (CAP)
Kumulativní profil přesnosti (CAP) ratingového modelu zobrazuje na ose x procento všech dlužníků a na ose y procento neplatičů. V marketingové analytice se nazýváGain Chart. V některých jiných oblastech se nazývá také křivka výkonu.
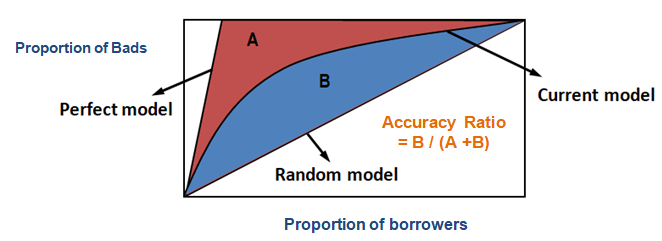
Pomocí CAP můžete porovnat křivku svého aktuálního modelu s křivkou „ideálního nebo dokonalého“ modelu a můžete ji také porovnat s křivkou náhodného modelu. ‚Dokonalý model‘ se vztahuje k ideálnímu stavu, v němž lze přímo zachytit všechny špatné zákazníky (požadovaný výsledek). „Náhodný model“ se vztahuje ke stavu, kdy je podíl špatných zákazníků rozdělen rovnoměrně. ‚Současný model‘ se týká vašeho modelu pravděpodobnosti selhání (nebo jiného modelu, na kterém pracujete). Vždy se snažíme sestavit model, který se přiklání (blíží) ke křivce dokonalého modelu. Aktuální model můžeme číst jako „% špatných zákazníků pokrytých na dané decilové úrovni“. Například 89 % špatných zákazníků zachycených pouhým výběrem 30 % nejlepších dlužníků na základě modelu.
- Odhadovanou pravděpodobnost selhání seřadíme sestupně a rozdělíme ji na 10 částí (decilů). To znamená, že nejrizikovější dlužníci s vysokou PD by měli být v horním decilu a nejbezpečnější dlužníci by se měli objevit v dolním decilu. Rozdělení skóre na 10 částí není pravidlem. Místo toho můžete použít ratingový stupeň.
- Vypočítejte počet dlužníků (pozorování) v každém decilu
- Vypočítejte počet špatných zákazníků v každém decilu
- Vypočítejte kumulativní počet špatných zákazníků v každém decilu
- Vypočtěte procento špatných zákazníků v každém decilu
- Vypočtěte kumulativní procento špatných zákazníků v každém decilu
.
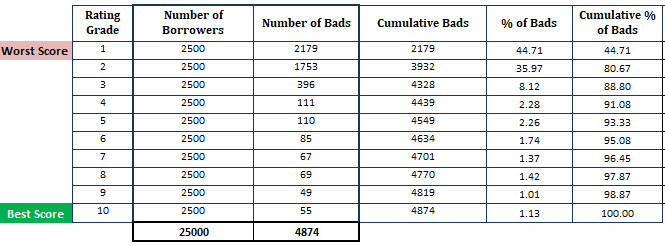
Dosud, jsme provedli výpočet na základě modelu PD (Nezapomeňte, že první krok vychází z pravděpodobností získaných z modelu PD).
Další krok : Jaký by měl být počet špatných zákazníků v každém decilu na základě dokonalého modelu?
- V dokonalém modelu by měl první decil zachytit všechny špatné zákazníky, protože první decil se týká nejhoršího ratingového stupně NEBO dlužníků s nejvyšší pravděpodobností selhání. V našem případě první decil nemůže zachytit všechny špatné zákazníky, protože počet dlužníků spadajících do prvního decilu je menší než celkový počet špatných zákazníků.
- Vypočtěte kumulativní počet špatných zákazníků v každém decilu na základě dokonalého modelu
- Vypočtěte kumulativní % špatných zákazníků v každém decilu na základě dokonalého modelu

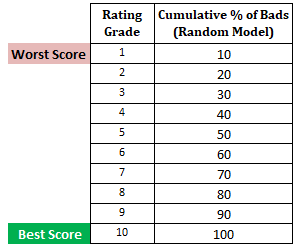
Další krok : Vypočtěte kumulativní procento špatných zákazníků v každém decilu na základě náhodného modeluV náhodném modelu by měl každý decil tvořit 10 %. Když vypočítáme kumulativní %, bude to 10 % v decilu 1, 20 % v decilu 2 a tak dále až do 100 % v decilu 10.
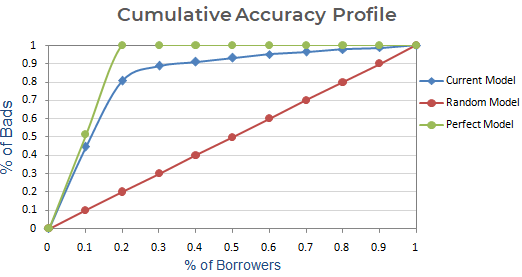
Další krok : Vytvořte graf s kumulativním % špatných na základě současného, náhodného a dokonalého modelu. Na ose x zobrazuje procento dlužníků (pozorování) a osa y představuje procento špatných zákazníků.
Poměr přesnosti
V případě CAP (Kumulativní profil přesnosti) je poměr přesnosti poměrem plochy mezi vaším současným prediktivním modelem a diagonální čarou a plochy mezi dokonalým modelem a diagonální čarou. Jinými slovy je to poměr zlepšení výkonnosti aktuálního modelu oproti náhodnému modelu a zlepšení výkonnosti dokonalého modelu oproti náhodnému modelu.
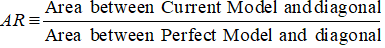
Prvním krokem je výpočet plochy mezi aktuálním modelem a diagonální přímkou. Plochu pod aktuálním modelem (včetně plochy pod diagonální čarou) můžeme vypočítat pomocí metody numerické integrace podle lichoběžníkového pravidla. Plocha lichoběžníku je
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) je šířka podintervalu a (yi + yi+1)*0,5 je průměrná výška.
V tomto případě x označuje hodnoty kumulativního podílu dlužníků na různých decilových úrovních a y označuje kumulativní podíl špatných zákazníků na různých decilových úrovních. Hodnota x0 a y0 je 0.
Po dokončení výše uvedeného kroku je dalším krokem odečtení 0,5 od plochy vrácené z předchozího kroku. Určitě vás zajímá relevance hodnoty 0,5. Je to plocha pod úhlopříčkou. Odečítáme proto, že potřebujeme pouze plochu mezi současným modelem a diagonální čarou (nazvěme ji B).
Nyní potřebujeme jmenovatel, což je plocha mezi dokonalým modelem a diagonální čarou, A + B. Je ekvivalentní 0.5*(1 - Prob(Bad)). Viz všechny kroky výpočtu uvedené v následující tabulce –
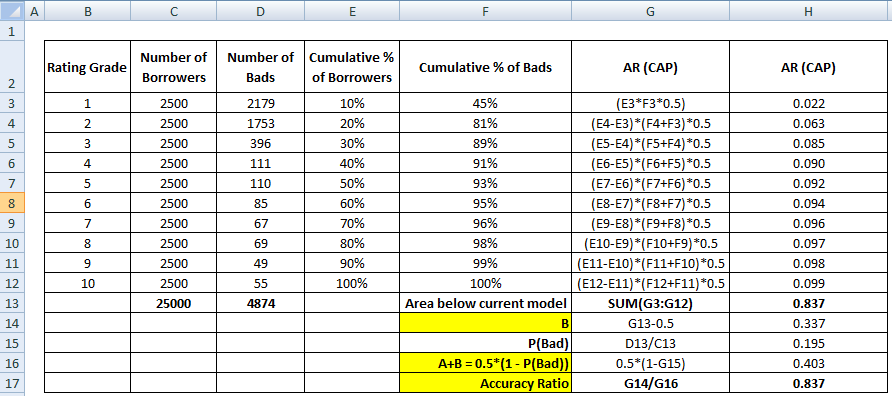
Jmenovatel AR lze také vypočítat stejně, jako jsme provedli výpočet čitatele. To znamená, že vypočítáme plochu pomocí „Kumulativního % dlužníků“ a „Kumulativního % špatných (dokonalý model)“ a pak od ní odečteme 0,5, protože nepotřebujeme uvažovat plochu pod úhlopříčkou.
V níže uvedeném kódu R jsme pro příklad připravili vzorová data. Název proměnné pred se týká předpovídaných pravděpodobností. Proměnná y označuje závislou proměnnou (skutečnou událost). K výpočtu poměru přesnosti potřebujeme pouze tyto dvě proměnné.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
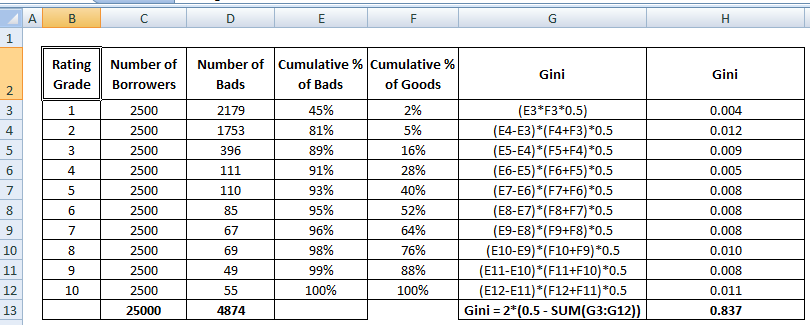
Giniho koeficient
Giniho koeficient je velmi podobný CAP, ale ukazuje podíl (kumulativně) dobrých zákazníků místo všech zákazníků. Ukazuje, do jaké míry má model lepší klasifikační schopnosti ve srovnání s náhodným modelem. Nazývá se také Giniho index. Giniho koeficient může nabývat hodnot od -1 do 1. Záporné hodnoty odpovídají modelu s obráceným významem hodnocení.
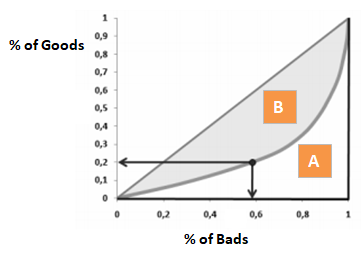
Gini = B / (A+B). Nebo Gini = 2B, protože plocha A + B je 0,5
Podívejte se na níže uvedené kroky výpočtu Giniho koeficientu :
Při odmítnutí x % dobrých zákazníků, kolik procent špatných zákazníků odmítneme vedle sebe.
Giniho koeficient je zvláštním případem Somerovy statistiky D. Pokud máte k dispozici procenta shody a neshody, můžete vypočítat Giniho koeficient.
Gini Coefficient = (Concordance percent - Discordance Percent)Procento konkordance se týká podílu dvojic, kde mají neplatiči vyšší předpokládanou pravděpodobnost než dobří zákazníci.
Procento diskordance se týká podílu dvojic, kde mají neplatiči nižší předpokládanou pravděpodobnost než dobří zákazníci.
Jiný způsob výpočtu Giniho koeficientu je pomocí procenta konkordance a diskordance (jak je vysvětleno výše). Viz níže uvedený kód R.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Jsou Giniho koeficient a poměr přesnosti ekvivalentní?
Ano, vždy se rovnají. Proto se Giniho koeficient někdy nazývá Accuracy Ratio (AR).
Ano, vím, že osy v Giniho koeficientu a AR se liší. Vyvstává otázka, jak to, že jsou stále stejné. Kdybyste vyřešili rovnici, zjistili byste, že plocha B v Giniho koeficientu je stejná jako plocha B / pravděpodobnost(dobra) v poměru přesnosti (což odpovídá (1/2)*AR ). Vynásobením obou stran číslem 2 získáte Gini = 2*B a AR = Plocha B / (Plocha A + B)
Plocha pod křivkou ROC (AUC)
Křivka RUC neboli ROC ukazuje podíl pravdivě pozitivních výsledků (neplatič je správně klasifikován jako neplatič) oproti podílu falešně pozitivních výsledků (neplatič je nesprávně klasifikován jako neplatič).
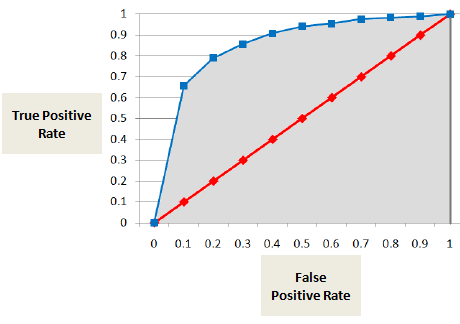
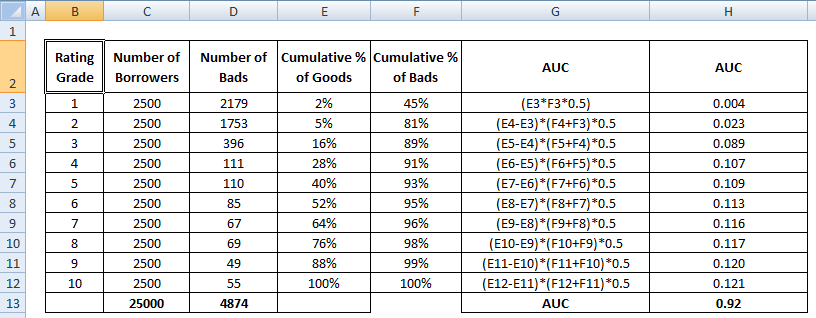
Skóre AUC je součtem všech jednotlivých hodnot vypočtených na úrovni ratingového stupně nebo decilu.
4 Metody výpočtu AUC Matematicky
Vztah mezi AUC a Giniho koeficientem
Gini = 2*AUC – 1.
Jistě vás zajímá, jak spolu souvisejí.
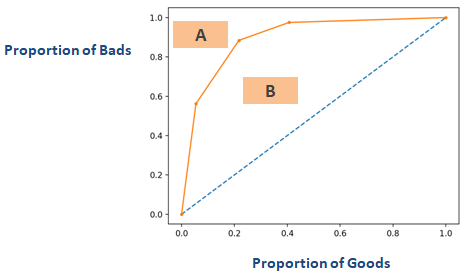
Pokud byste obrátili osu grafu zobrazeného ve výše uvedené části s názvem „Giniho koeficient“, dostali byste podobný graf jako níže. Zde Gini = B / (A + B). Plocha A + B je 0,5, takže Gini = B / 0,5, což zjednodušeně znamená Gini = 2*B. AUC = B + 0.5, což se dále zjednoduší na B = AUC – 0,5. Tuto rovnici dosaďte do Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1
.