- Reverzní inženýrství Xero pro výuku SQL
- Účetnictví 101
- Implementace účetnictví v systému Xero
- Transakční cykly
- Vnitřní kontrola
- Caveat: Nejdeme do králičí nory
- ZákladySQL
- Prezentace dat je oddělena od jejich uložení.
- Tabulky jsou obvykle vzájemně propojeny tak, aby tvořily vztah.
- Návrh naší implementace systému Xero
- Implementace naší verze v SQL
- Přidání obsahu do naší databáze
- Vytvoření finančních výkazů z naší databáze
- Dobře! Zvládli jste to
Reverzní inženýrství Xero pro výuku SQL
Svědí vás to.
Tuto radu dávám vždy, když se mě někdo zeptá, jak se naučit programovat. Prakticky to znamená, že musíte řešit věci nebo si vybírat projekty, které se vás týkají – ať už v práci, nebo v osobním životě.
Bezmyšlenkovité sledování tutoriálů na Youtube, čtení knih o programování, kopírování kódu z příspěvků na Redditu atd. nikam nevede, pokud se začínáte učit programovat.
V tomto příspěvku vám ukážu, jak vytvořit hrubou účetní databázi pomocí SQLite.
Takže, proč vytvářet účetní databázi? Proč prostě nezkopírujete veřejná data, nestrčíte je do SQLite a neprocvičíte si to odtud?
Důvodem je, že vytvoření účetní databáze je dostatečně pokročilé, aby pokrylo všechny aspekty databází a jazyka SQL – od dotazů přes spoje až po pohledy a CTE.
Jako člověk z účetního prostředí si myslím, že je to nejlepší projekt, jak se naučit SQL. Programování je přece nástroj k řešení problémů. Tudíž by mohl rovnou „vyřešit“ nějaký obtížný, aby se plně naučil SQL.
Inspiraci k vytvoření účetního systému pomocí SQL jsem získal pozorováním, jak funguje Xero. Pro ty, kteří ho neznají, Xero je cloudový účetní software pocházející z Nového Zélandu. Nyní se rozšířil do Austrálie, USA, Kanady a Velké Británie.
Na systému Xero je dobré to, že má pěkné a přehledné rozhraní a na výběr spoustu aplikací, které rozšiřují jeho funkce.
Upozornění: Nejsem inženýr ani vývojář společnosti Xero a tyto postřehy nemusí přesně odpovídat tomu, jak systém funguje, protože je neustále aktualizován. Určitě zde prezentovaný SQL není přesný návrh SQL, který Xero používá, protože jejich systém musí škálovat. Ale je to velmi zajímavý projekt, tak se do toho pojďme pustit!“
Účetnictví 101
Než se začnete příliš těšit, pojďme si nejprve udělat rychlokurz účetnictví.
Základní účetní rovnice zní
Aktiva = závazky + vlastní kapitál
Tato rovnice má v podstatě tři části
- Aktiva jsou všechny zdroje účetní jednotky.
- Závazky jsou to, co firma dluží.
- a Vlastní kapitál, souhrn všech investic vlastníka, čerpání, zisk nebo ztráta.
Pravá strana popisuje, jak byla aktiva financována – buď prostřednictvím pasiv, nebo vlastního kapitálu.
Výše uvedenou rovnici můžeme rozšířit o rozdělení Vlastního kapitálu
Aktiva = Závazky + Počáteční vlastní kapitál + Výnosy – Náklady
Těchto 5 účtů – Aktiva, Závazky, Vlastní kapitál, Výnosy, & Náklady – jsou typy účtů, se kterými se obvykle setkáváme v účetním systému.
Pak je tu pojem Debet a Kredit. Mohl bych pokračovat a probrat je do hloubky, ale pro tento příspěvek vám stačí vědět, že v každé transakci:
Debet = Kredit
Tyto dvě rovnice obecně řídí, co se děje v celém účetním cyklu. Tyto dvě rovnice nám také poslouží jako vodítko při vytváření vlastní účetní databáze.
Jelikož pocházím z účetního prostředí, myslím si, že je to nejlepší projekt, jak se naučit SQL. Programování je přece nástroj k řešení problémů. Tudíž by mohl rovnou „vyřešit“ nějaký obtížný, aby se plně naučil SQL.
Implementace účetnictví v systému Xero
Důležité je si uvědomit, že systém Xero je navržen tak, aby byl užitečný majitelům firem (ne účetním) při každodenní činnosti firmy.
Jako takové je navrženo na základě transakčních cyklů a interní kontroly.
Transakční cykly
Základní transakční cykly jsou následující
- Prodejní cyklus
- Nákupní cyklus
- Kasový cyklus
Xero implementuje tyto cykly následovně
Prodejní cyklus
Prodej se do Xero zadává pomocí faktur. Představte si, že podnik vystavuje skutečné papírové faktury za tržby (tržby v hotovosti nebo na účet). To je přesně to, co chce Xero replikovat.
Faktury lze tisknout přímo z programu a jsou automaticky číslovány vzestupnou řadou.
Pod kapotou faktury zvyšují účet Tržby a účet Pohledávky (AR).
Cyklus Nákupy
Účty se do Xero zadávají pomocí Účty. Opět si představte, že podnik vystavuje skutečné účty za nákupy (nákupy v hotovosti nebo na účet). To je obvyklý případ pro komunální služby a zásoby. To je také věc, kterou chce Xero replikovat.
Účty lze tisknout přímo ze softwaru a lze je použít k doplnění všech schvalovacích postupů prováděných podnikem.
Pod kapotou účty zvyšují účet Nákupy a účet Závazky (ZP).
Kasový cyklus
To zahrnuje všechny transakce týkající se hotovosti. Existují 4 typy
- Platby faktur – platby neuhrazených faktur
- Platby účtů – platby neuhrazených účtů
- Přijaté peníze – hotovostní příjmy, které nejsou platbami faktur. Může se jednat o hotovostní tržby, ale pokud se chystáte vystavit fakturu, použijte funkci Faktury
- Utržené peníze – výplaty hotovosti, které nejsou platbami účtů. Může se jednat o nákupy v hotovosti, ale pokud se chystáte vystavit fakturu, použijte funkci Účty.
To je na části transakčních cyklů.
Vnitřní kontrola
Pro vnitřní kontrolu musíte pochopit pojem systémové účty.
Xero má obsáhlý článek pro pochopení systémových účtů zde. Pro naše účely se však budeme zabývat pouze následujícími systémovými účty
- Příjemky
- Závazky
- Bankovní účty (ve vazbě na bankovní kanály)
Tyto účty nelze použít v ručních denících. To znamená, že Xero chce, abyste k podpoře zůstatků těchto účtů používali faktury, účty a peněžní transakce (platby faktur, platby účtů, přijaté peníze a vydané peníze). Jedná se o implementaci vnitřní kontroly v systému Xero, chcete-li.
Samozřejmě můžete použít nesystémovou verzi účtů AR, AP a Banka tak, že je vytvoříte v účtové osnově (COA). Nemůžete však pro ně používat typy účtů AR, AP a Banka.
Důležité je si uvědomit, že systém Xero je navržen tak, aby byl užitečný majitelům firem (nikoli účetním) při každodenním provozu firmy.
Caveat: Nejdeme do králičí nory
Navržení účetnictví je opravdu složité. Jen na pokrytí tohoto tématu by bylo potřeba více příspěvků na blogu. Proto si pro zjednodušení vytvoříme následující předpoklady (není to přesně tak, jak je implementuje Xero)
- Platby faktur a účtů
Platby faktur mohou zaplatit dvě nebo více faktur vcelku. To znamená, že neumožníme částečné platby. Totéž platí pro Platby faktur. - Inventura
Nebudeme zde používat položky inventury. Pro prodeje nebo nákupy budeme používat přímo účet Zásoby, nikoliv vytvářet skladové položky, které se mapují na účet Zásoby.
To je vše k našim předpokladům. Po návrhu naší databáze může čtenář tyto předpoklady zrušit a pokusit se co nejvíce napodobit systém Xero.
ZákladySQL
Nyní si před rekonstrukcí naší verze struktury databáze systému Xero udělejme rychlokurz o databázích.
Databáze je kolekce tabulek. Každá tabulka se skládá z řádků dat, kterým se říká záznamy. Sloupce se nazývají pole.
Program pro práci s databází se nazývá systém pro správu databází neboli DBMS. Jako jednoduché přirovnání lze DBMS přirovnat k programu Excel, databázi k sešitu Excelu a tabulku k listu Excelu.
Mezi databází a sešitem Excelu jsou dva hlavní rozdíly.
Prezentace dat je oddělena od jejich uložení.
To znamená, že data v databázi nelze upravovat tak, že přejdete přímo k datům a upravíte je. (Jiné programy DBMS mají grafická uživatelská rozhraní, která umožňují přímý přístup k datům v databázi a jejich úpravu jako v tabulkovém procesoru. Pod kapotou však tato akce vydává příkaz SQL).
Tabulky jsou obvykle vzájemně propojeny tak, aby tvořily vztah.
Vztahy mohou být one-to-one, one-to-many nebo many-to-many.
Vztah one-to-one znamená „řádek tabulky souvisí pouze s jedním řádkem v jiné tabulce a naopak“. Příkladem může být vztah jméno zaměstnance k daňovému identifikačnímu číslu.
Tento druh se obvykle zahrnuje do jedné tabulky Zaměstnanci, protože ve skutečnosti není žádný přínos z rozdělení dat do dvou tabulek.
Vztah jeden k mnoha naopak znamená „řádek tabulky souvisí pouze s jedním nebo více řádky v jiné tabulce, ale ne naopak“. Příkladem jsou faktury k řádkům faktur. Faktura může mít více řádků, ale řádek faktury patří pouze ke konkrétní faktuře.
A jak jste asi uhodli, many-to-many znamená „řádek tabulky souvisí pouze s jedním nebo více řádky v jiné tabulce a naopak“. Příkladem může být systém, který implementuje částečné platby.
Faktura může být částečně uhrazena různými platebními transakcemi a platba může částečně uhradit různé faktury.
Jak by databáze tyto vztahy poznala?
Je to jednoduché. Je to pomocí primárních a cizích klíčů.
Primární klíče jsou nutné k odlišení jednoho řádku od druhého. Jednoznačně identifikují každý řádek dat v tabulce.
Cizí klíče jsou naopak primární klíče z jiné tabulky. Vztažením primárních klíčů a cizích klíčů tedy přetrvávají databázové vztahy.
Při vztahu jedna-více obsahuje strana „jedna“ primární klíč a strana „mnoho“ obsahuje tento primární klíč jako svůj cizí klíč. V našem výše uvedeném příkladu se pro získání všech řádků náležejících k faktuře dotazujeme do tabulky InvoiceLines, kde se cizí klíč rovná konkrétnímu číslu faktury.
Při vztahu many to many je vztah rozdělen na dva vztahy one-to-many pomocí třetí tabulky nazývané „spojovací“. Například náš systém částečných plateb bude mít jako spojovací tabulku tabulku Faktury, tabulku Platby a tabulku FakturyPlatby. Primárními klíči tabulky InvoicePayments bude složený klíč složený z primárních klíčů tabulek Invoices a Payments takto

.
Všimněte si, že spojovací tabulka neobsahuje žádné další údaje, protože kromě spojení tabulek Faktury a Platby nemá žádný jiný účel.
Chceme-li získat faktury uhrazené určitou platební transakcí, řekněme PAY 1, spojíme tabulky Faktury a Platby prostřednictvím spojovací tabulky a zeptáme se na payment_id = "PAY 1".
Tolik k základům databáze. Nyní jsme připraveni navrhnout naši databázi.
Podle jednoduché analogie je DBMS jako program Excel, databáze jako sešit Excelu a tabulka jako list Excelu.
Teď, když máme základní znalosti o systému Xero, můžeme začít vytvářet hrubý náčrt struktury jeho databáze. Všimněte si, že budu používat formát Table_Name. To jsou slova psaná velkými písmeny oddělená podtržítky. Budu také používat množné číslo pro názvy tabulek.
Pro prodejní cyklus, budeme mít následující tabulky
- Faktury
- Zákazníci – zákazník může mít mnoho faktur, ale faktura nemůže patřit mnoha zákazníkům
- Faktury_Platby – prozatím si pamatujte náš předpoklad, že mezi Fakturami_Platbami, respektive Fakturami, je vztah jedna k mnoha (žádné částečné platby)
- Faktura_Čáry – jedná se o spojovací tabulku mezi Fakturami a COA. Jeden účet se může objevit ve více fakturách a jedna faktura může mít více účtů.
- Účtová osnova (COA)
Pro cyklus Nákupy, budeme mít následující tabulky
- Účty
- Dodavatelé – dodavatel může mít mnoho účtů, ale jeden účet nemůže patřit mnoha dodavatelům
- Účty_Platby – prozatím si pamatujte náš předpoklad, že mezi účty_Platby a účty existuje vztah jedna k mnoha, respektive
- Účty_Linky – jedná se o spojovací tabulku mezi účty a COA. Jeden účet se může objevit ve více účtech a jeden účet může mít více účtů.
- COA – stejně jako výše v cyklu prodeje. Uvádím jen pro úplnost.
Pro peněžní cyklus, budeme mít následující tabulky (Platební tabulky jsme již vytvořili výše)
- Přijaté_peněžní prostředky – může mít volitelného zákazníka
- Přijaté_peněžní prostředky_řádky – jedná se o spojování tabulka mezi Received_Moneys a COA
- Spent_Moneys – může mít nepovinného Dodavatele
- Spent_Money_Lines – jedná se o spojovací tabulku mezi Spent_Moneys a COA
Koncepčně, struktura naší databáze je následující
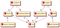
Tento diagram se v databázové hantýrce nazývá Entity-Relationship Diagram neboli ERD. Vztahy one-to-many se označují 1 – M a many-to-many M – M.
Ve výše uvedeném diagramu nejsou zobrazeny spojovací tabulky, protože jsou implicitně obsaženy v tabulkách se vztahy many-to-many.
Implementace naší verze v SQL
Nyní je čas implementovat náš model v SQL. Začněme nejprve definováním některých konvencí.
Primární klíč bude mít název pole/sloupce id a cizí klíč bude mít formát table_id, kde table je název tabulky strany „mnoho“ v jednotném čísle. Například v tabulce Faktury bude cizí klíč customer_id.
Čas pro kód SQL. Zde je:
Několik věcí:
- SQL příkazy nerozlišují velikost písmen,
CREATE TABLEje stejný jakocreate table - Příkazy
IF EXISTSaIF NOT EXISTSjsou nepovinné. Používám je jen proto, abych zabránil chybám v příkazech SQL. Pokud například vypustím neexistující tabulku, SQLite vyhodí chybu. Také jsem dalIF NOT EXISTSna příkaz create table, abychom omylem nepřepsali nějakou existující tabulku. - Dejte si pozor na příkaz
DROP TABLE! Bez varování odstraní existující tabulku, i když má obsah. - Názvy tabulek lze také psát s velkými písmeny nebo bez nich. Pokud názvy tabulek obsahují mezery, měly by být uzavřeny zpětnými tečkami (`). Nerozlišují se u nich velká a malá písmena.
SELECT * FROM Customersje stejný jakoselect * from customers.
Přestože je jazyk SQL, co se týče syntaxe, poněkud uvolněný, měli byste se snažit zachovat konzistenci v kódu SQL.
Vezměte také na vědomí vztahy uvedené v ERD výše. Nezapomeňte také, že cizí klíč je na mnoha stranách.
Pořadí je důležité, protože některé tabulky slouží jako závislost na jiné kvůli cizímu klíči. Například musíte nejprve vytvořit tabulku Invoice_Payments a teprve poté tabulku Invoice, protože ta je na ní závislá. Trik zde spočívá v tom, že začnete od okrajů ERD, protože ty mají nejmenší počet cizích klíčů.
Na tomto odkazu si také můžete stáhnout ukázkovou databázi v SQLite bez obsahu.
Pro její zobrazení můžete použít bezplatný a otevřený prohlížeč SQLite Browser. Stáhněte si jej zde!
Přidání obsahu do naší databáze
Teď, když máme ukázkovou databázi, do ní vložíme data. Vzorová data si můžete stáhnout odsud – stačí je podle potřeby rozdělit do CSV.
Vezměte na vědomí, že kredity se zobrazují jako kladné a záporné.
Pro tento příspěvek jsem pouze použil funkci DB Browser pro import CSV z výše uvedeného souboru Excel. Například pro import souboru Zákazníci.csv
- Zvolte tabulku Zákazníci
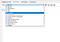
- Přejděte na Soubor > Import > Tabulka ze souboru CSV a zvolte Zákazníci.csv
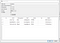
- Klikněte na Ok/Yes na všechny následující výzvy k importu dat.
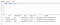
Pokud zadáte následující příkaz SQL, měli by se zobrazit všichni Zákazníci v naší databázi
Vytvoření finančních výkazů z naší databáze
Abychom dokázali, že naše databáze funguje jako hrubý účetní systém, vytvoříme Rozvahu.
Prvním krokem je vytvoření transakčních zobrazení pro naše transakce Faktury, Účty, Přijaté_peníze a Utracené_peníze. Kód bude vypadat následovně
V prvních dvou příkazech použiji CTE (s klíčovým slovem recursive). CTE jsou užitečné, protože spojuji 4 tabulky, abych získal jediný pohled na transakce Faktury a odpovídající platby. Více nad CTE v SQLite byste se mohli dozvědět zde.
Po provedení výše uvedeného příkazu by vaše databáze měla mít následující 4 pohledy.
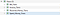
Nakonec vytvoříme kód pro Trial Balance neboli zkráceně TB. Všimněte si, že TB je pouze kolekcí zůstatků našich transakcí s přihlédnutím k pravidlům, která jsme si stanovili při návrhu naší databáze.
Kód je následující
Výše uvedený kód obsahuje několik SQL dotazů spojených příkazem union all. Jednotlivé dotazy jsem opatřil poznámkami, abych ukázal, čeho se každý z nich snaží dosáhnout.
Například první dotaz se snaží získat všechny kredity pro fakturační transakce (většinou Prodej). Druhý pro debety transakcí Faktury (většinou Nákupy) atd.
Provedení by mělo vést k následujícímu TB.
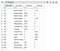
To si můžete dát do Excelu a zkontrolovat, že debety se rovnají kreditům (což jsem udělal). Celkový součet debetů a kreditů je 14115 a -14115.
Dobře! Zvládli jste to
Vytvořit účetní systém je opravdu složité. V podstatě jsme prozkoumali celou škálu návrhu databáze – od koncepce přes ERD a její vytvoření až po dotazování. Poplácejte se po zádech, že jste se dostali až sem.
Vezměte na vědomí, že jsme naši databázi záměrně omezili, abychom se více zaměřili na koncepty. Můžete je zrušit a zkusit vytvořit jinou bez omezení.
To je vše! Nyní je z vás SQL ninja! Gratulujeme!
Podívejte se na mou druhou knihu Návrh účetních databází, která brzy vyjde na Leanpubu!
Podívejte se také na mou první knihu PowerQuery Guide to Pandas na Leanpubu.
Sledujte mě na Twitteru a Linkedin.
Sledujte mě na Twitteru a Linkedin.