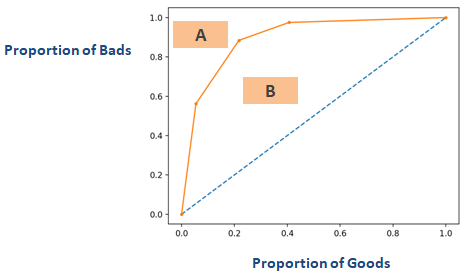
Kumulativ nøjagtighedsprofil (CAP)
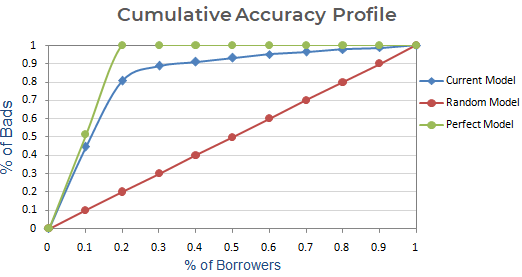
Kumulativ nøjagtighedsprofil (CAP) for en kreditvurderingsmodel viser procentdelen af alle låntagere (debitorer) på x-aksen og procentdelen af misligholdere (dårlige kunder) på y-aksen. Inden for marketinganalyse kaldes detGain Chart. Den kaldes også Power Curve på nogle andre områder.
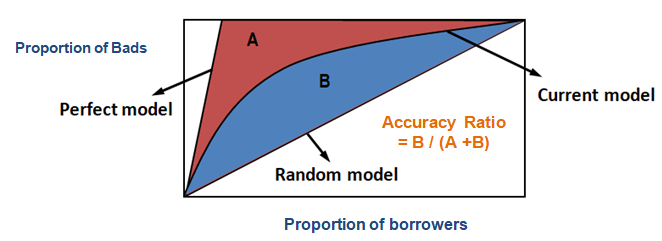
Ved hjælp af CAP kan du sammenligne kurven for din nuværende model med kurven for den “ideelle eller perfekte” model og kan også sammenligne den med kurven for en tilfældig model. ‘Perfekt model’ henviser til den ideelle tilstand, hvor alle de dårlige kunder (ønsket resultat) kan indfanges direkte. Tilfældig model” henviser til den tilstand, hvor andelen af dårlige kunder er ligeligt fordelt. “Nuværende model” henviser til din model for sandsynlighed for misligholdelse (eller enhver anden model, du arbejder på). Vi forsøger altid at opbygge den model, der hælder mod (tættere) på kurven for den perfekte model. Vi kan læse den nuværende model som “% af dårlige kunder dækket på et givet decilniveau”. F.eks. 89 % af de dårlige kunder er dækket ved blot at udvælge de 30 % bedste debitorer baseret på modellen.
- Sorter den estimerede sandsynlighed for misligholdelse i faldende orden og opdel den i 10 dele (decil). Det betyder, at de mest risikable låntagere med høj PD skal være i den øverste decil og de sikreste låntagere skal være i den nederste decil. Opdeling af scoren i 10 dele er ikke en tommelfingerregel. I stedet kan du bruge ratinggrad.
- Beregne antal låntagere (observationer) i hver decil
- Beregne antal dårlige kunder i hver decil
- Beregne kumulativt antal dårlige kunder i hver decil
- Beregne kumulativt antal dårlige kunder i hver decil
- Beregne procentdel dårlige kunder i hver decil
- Beregne kumulativ procentdel dårlige kunder i hver decil
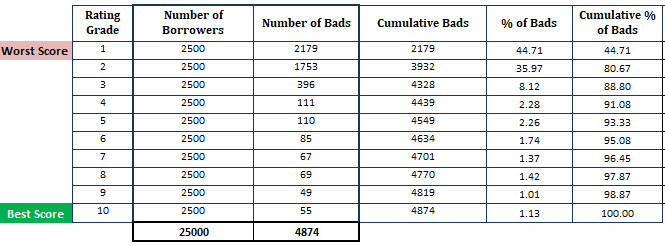
Sådan er det nu, har vi foretaget beregninger baseret på PD-modellen (Husk, at første trin er baseret på de sandsynligheder, der er opnået fra PD-modellen).
Næste skridt: Hvad skal antallet af dårlige kunder i hver decil være baseret på perfekt model?
- I perfekt model skal første decil indfange alle de dårlige kunder, da første decil henviser til den dårligste ratingklasse ELLER låntagere med størst sandsynlighed for misligholdelse. I vores tilfælde kan første decil ikke indfange alle de dårlige kunder, da antallet af låntagere, der falder i første decil, er mindre end det samlede antal dårlige kunder.
- Beregn det kumulative antal dårlige kunder i hver decil baseret på perfekt model
- Beregn den kumulative % af dårlige kunder i hver decil baseret på perfekt model

Næste trin: Beregn den kumulative procentdel af dårlige kunder i hver decil baseret på tilfældig modelI tilfældig model skal hver decil udgøre 10 %. Når vi beregner den kumulative %, vil den være 10 % i decil 1, 20 % i decil 2 osv. indtil 100 % i decil 10.
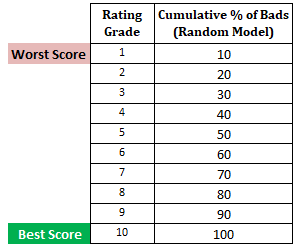
Næste trin : Opret et plot med kumulativ % dårlige kunder baseret på nuværende, tilfældig og perfekt model. På x-aksen vises procentdelen af låntagere (observationer), og y-aksen repræsenterer procentdelen af dårlige kunder.
Nøjagtighedsforhold
I tilfælde af CAP (Cumulative Accuracy Profile) er nøjagtighedsforholdet forholdet mellem arealet mellem din nuværende prædiktive model og den diagonale linje og arealet mellem den perfekte model og den diagonale linje. Med andre ord er det forholdet mellem ydelsesforbedringen af den nuværende models ydeevne i forhold til den tilfældige model og ydelsesforbedringen af den perfekte models ydeevne i forhold til den tilfældige model.
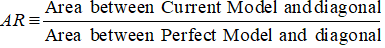
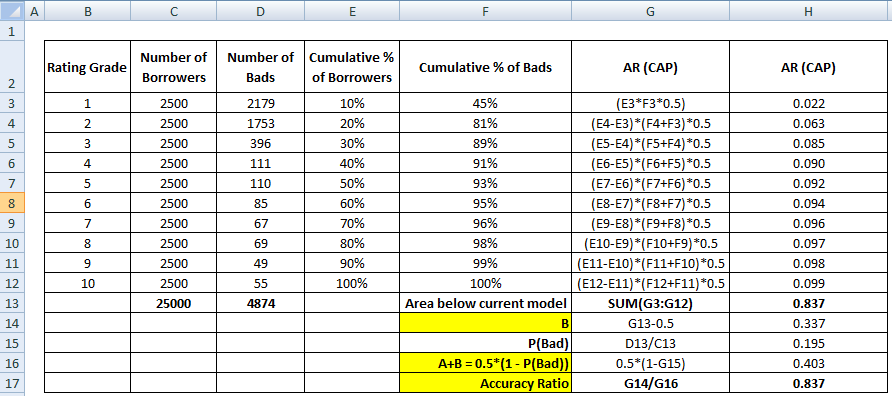
Det første skridt er at beregne området mellem den nuværende model og den diagonale linje. Vi kan beregne arealet under den aktuelle model (herunder arealet under den diagonale linje) ved hjælp af den numeriske integrationsmetode med trapezregel. Arealet af et trapez er
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) er bredden af underintervallet, og (yi + yi+1)*0,5 er den gennemsnitlige højde.
I dette tilfælde henviser x til værdierne for den kumulative andel af låntagere på forskellige decilniveauer, og y henviser til den kumulative andel af dårlige kunder på forskellige decilniveauer. Værdien af x0 og y0 er 0.
Når ovenstående trin er gennemført, er næste trin at trække 0,5 fra det areal, der er returneret fra det foregående trin. Du skal undre dig over relevansen af 0,5. Det er arealet under den diagonale linje. Vi trækker det fra, fordi vi kun har brug for arealet mellem den aktuelle model og den diagonale linje (lad os kalde det B).
Nu har vi brug for nævneren, som er arealet mellem den perfekte model og den diagonale linje, A + B. Det svarer til 0.5*(1 - Prob(Bad)). Se alle beregningstrin vist i tabellen nedenfor –
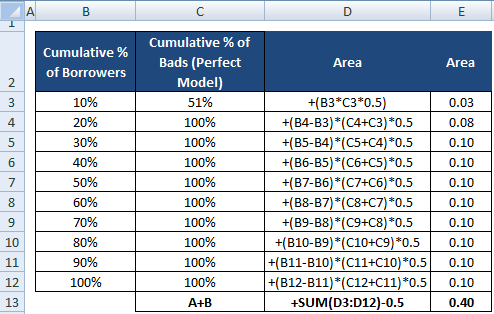
Nævneren af AR kan også beregnes, ligesom vi udførte beregningen for tælleren. Det betyder, at vi beregner arealet ved hjælp af “Kumulativ % af låntagere” og “Kumulativ % af dårlige låntagere (perfekt model)” og derefter trækker 0,5 fra det, da vi ikke behøver at overveje arealet under den diagonale linje.
I R-koden nedenfor har vi forberedt eksempeldata til eksempel. Variabelnavn pred henviser til forudsagte sandsynligheder. Variabel y henviser til afhængig variabel (faktisk begivenhed). Vi har kun brug for disse to variabler til at beregne Accuracy Ratio.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Gini-koefficient
Gini-koefficienten minder meget om CAP, men den viser andelen (kumulativ) af gode kunder i stedet for alle kunder. Den viser, i hvilket omfang modellen har bedre klassificeringsevne i forhold til den tilfældige model. Den kaldes også Gini-indeks. Gini-koefficienten kan antage værdier mellem -1 og 1. Negative værdier svarer til en model med omvendt betydning af scorer.
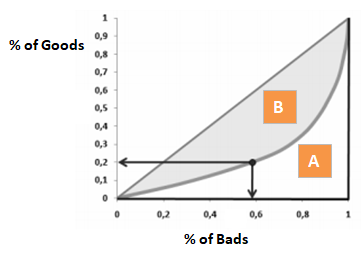
Gini = B / (A+B). Eller Gini = 2B, da arealet af A + B er 0,5
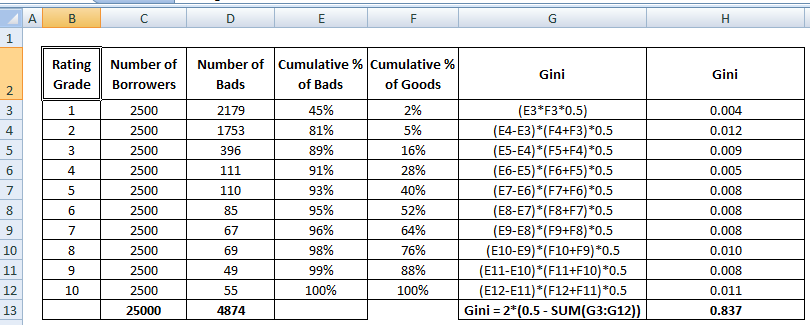
Se beregningstrinene for Gini-koefficienten nedenfor :
Ved at afvise x% af de gode kunder, hvilken procentdel af de dårlige kunder afviser vi så ved siden af.
Gini-koefficienten er et specialtilfælde af Somers D-statistik. Hvis du har procentvis concordance og discordance, kan du beregne Gini-koefficienten.
Gini Coefficient = (Concordance percent - Discordance Percent)Concordance procent refererer til andelen af par, hvor misligholdere har en højere forudsagt sandsynlighed end de gode kunder.
Discordance procent refererer til andelen af par, hvor misligholdere har en lavere forudsagt sandsynlighed end de gode kunder.
En anden måde at beregne Gini-koefficienten på er ved at bruge concordance og discordance procent (som forklaret ovenfor). Se R-koden nedenfor.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Er Gini-koefficienten og nøjagtighedskvotienten ækvivalente?
Ja, de er altid lige store. Derfor kaldes Gini-koefficienten nogle gange Accuracy Ratio (AR).
Ja, jeg ved godt, at akserne i Gini og AR er forskellige. Spørgsmålet rejser sig, hvordan de stadig er ens. Hvis du løser ligningen, vil du opdage, at område B i Gini-koefficienten er det samme som område B / Prob(Good) i nøjagtighedskvotienten (hvilket svarer til (1/2)*AR ). Hvis man multiplicerer begge sider med 2, får man Gini = 2*B og AR = Område B / (Område A + B)
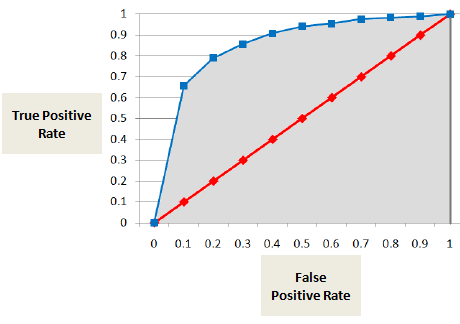
Area under ROC-kurven (AUC)
AUC eller ROC-kurven viser andelen af rigtige positive resultater (misligholdere klassificeres korrekt som misligholdere) i forhold til andelen af falske positive resultater (ikke-misligholdere klassificeres fejlagtigt som misligholdere).
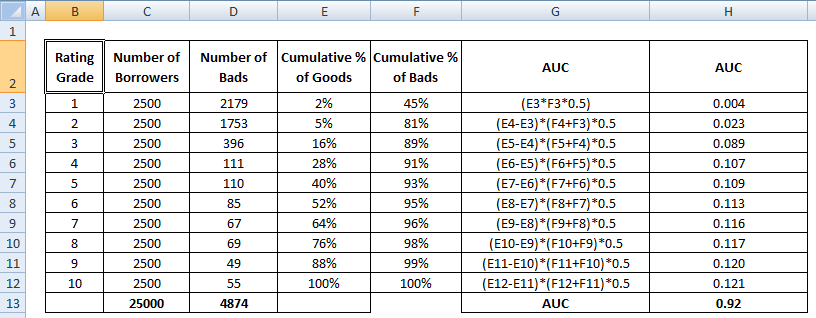
AUC-score er summen af alle de individuelle værdier, der er beregnet på ratingklasse- eller decilniveau.
4 Metoder til beregning af AUC Matematisk
Sammenhæng mellem AUC og Gini-koefficient
Gini = 2*AUC – 1.
Du undrer dig sikkert over, hvordan de hænger sammen.
Hvis du vender aksen i det diagram, der er vist i ovenstående afsnit med navnet “Gini-koefficient”, vil du få et diagram, der ligner nedenstående diagram. Her Gini = B / (A + B). Arealet af A + B er 0,5, så Gini = B / 0,5, hvilket forenkles til Gini = 2*B. AUC = B + 0.5, som yderligere forenkles til B = AUC – 0,5. Sæt denne ligning i Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1