Kumulatives Genauigkeitsprofil (CAP)
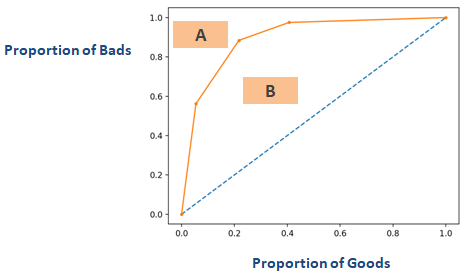
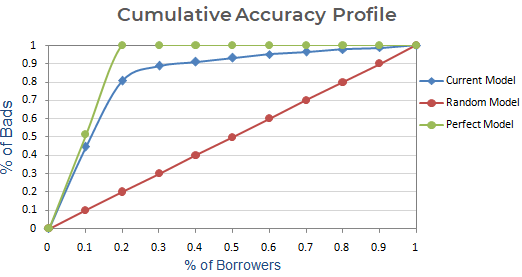
Das kumulative Genauigkeitsprofil (CAP) eines Kredit-Rating-Modells zeigt auf der x-Achse den Prozentsatz aller Kreditnehmer (Schuldner) und auf der y-Achse den Prozentsatz der säumigen Kunden (schlechte Kunden). In der Marketinganalytik wird sieGain Chartgenannt. In einigen anderen Bereichen wird sie auch Power Curve genannt.
Durch die Verwendung von CAP können Sie die Kurve Ihres aktuellen Modells mit der Kurve eines „idealen oder perfekten“ Modells vergleichen und auch mit der Kurve eines Zufallsmodells. Das „perfekte Modell“ bezieht sich auf den idealen Zustand, in dem alle schlechten Kunden (gewünschtes Ergebnis) direkt erfasst werden können. Das „Zufallsmodell“ bezieht sich auf den Zustand, in dem der Anteil der schlechten Kunden gleichmäßig verteilt ist. Aktuelles Modell“ bezieht sich auf Ihr Ausfallwahrscheinlichkeitsmodell (oder ein anderes Modell, an dem Sie gerade arbeiten). Wir versuchen immer, das Modell zu erstellen, das sich der Kurve des perfekten Modells annähert. Wir können das aktuelle Modell als „% der schlechten Kunden, die in einem bestimmten Dezil abgedeckt sind“ lesen. Zum Beispiel werden 89 % der uneinsichtigen Kunden erfasst, wenn nur die 30 % der Schuldner mit dem Modell ausgewählt werden.
- Sortieren Sie die geschätzte Ausfallwahrscheinlichkeit in absteigender Reihenfolge und teilen Sie sie in 10 Teile (Dezile). Das bedeutet, dass die risikoreichsten Kreditnehmer mit hoher Ausfallwahrscheinlichkeit im obersten Dezil und die sichersten Kreditnehmer im untersten Dezil zu finden sein sollten. Die Aufteilung der Punktzahl in 10 Teile ist keine Faustregel. Stattdessen können Sie die Ratingnote verwenden.
- Berechnen Sie die Anzahl der Kreditnehmer (Beobachtungen) in jedem Dezil
- Berechnen Sie die Anzahl der schlechten Kunden in jedem Dezil
- Berechnen Sie die kumulative Anzahl der schlechten Kunden in jedem Dezil
- Berechnung des prozentualen Anteils der schlechten Kunden in jedem Dezil
- Berechnung des kumulativen prozentualen Anteils der schlechten Kunden in jedem Dezil
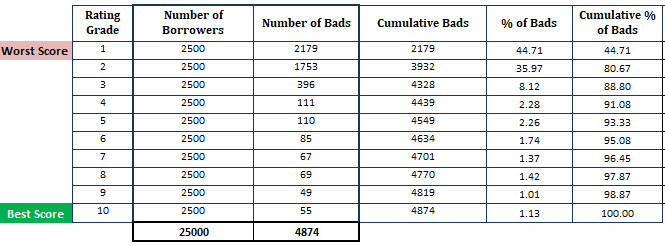
Bis jetzt, haben wir die Berechnung auf der Grundlage des PD-Modells durchgeführt (denken Sie daran, dass der erste Schritt auf den aus dem PD-Modell gewonnenen Wahrscheinlichkeiten basiert).
Nächster Schritt: Wie hoch sollte die Anzahl der schlechten Kunden in jedem Dezil auf der Grundlage des perfekten Modells sein?
- Im perfekten Modell sollte das erste Dezil alle schlechten Kunden erfassen, da sich das erste Dezil auf die schlechteste Ratingstufe ODER die Kreditnehmer mit der höchsten Ausfallwahrscheinlichkeit bezieht. In unserem Fall kann das erste Dezil nicht alle schlechten Kunden erfassen, da die Zahl der Kreditnehmer, die in das erste Dezil fallen, geringer ist als die Gesamtzahl der schlechten Kunden.
- Berechnen Sie die kumulative Anzahl der schlechten Kunden in jedem Dezil auf der Grundlage des perfekten Modells
- Berechnen Sie den kumulativen Prozentsatz der schlechten Kunden in jedem Dezil auf der Grundlage des perfekten Modells

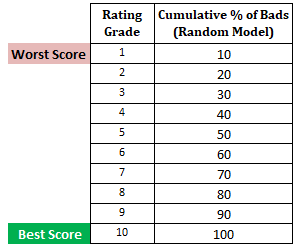
Nächster Schritt: Berechnen Sie den kumulativen Prozentsatz der schlechten Kunden in jedem Dezil auf der Grundlage des ZufallsmodellsIm Zufallsmodell sollte jedes Dezil 10 % ausmachen. Wenn wir den kumulativen Prozentsatz berechnen, beträgt er 10 % im Dezil 1, 20 % im Dezil 2 und so weiter bis zu 100 % im Dezil 10.
Nächster Schritt: Erstellen Sie ein Diagramm mit dem kumulativen Prozentsatz der schlechten Kunden auf der Grundlage des aktuellen, des Zufalls- und des perfekten Modells. Auf der x-Achse wird der Prozentsatz der Kreditnehmer (Beobachtungen) und auf der y-Achse der Prozentsatz der schlechten Kunden dargestellt.
Genauigkeitsquotient
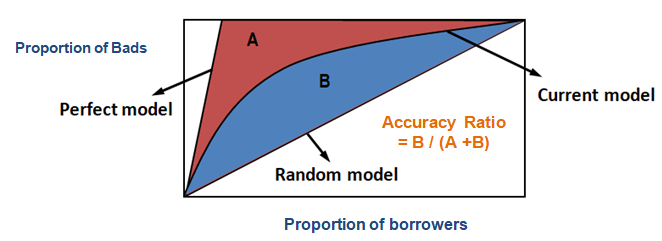
Im Falle des CAP (Cumulative Accuracy Profile) ist der Genauigkeitsquotient das Verhältnis der Fläche zwischen Ihrem aktuellen Vorhersagemodell und der diagonalen Linie und der Fläche zwischen dem perfekten Modell und der diagonalen Linie. Mit anderen Worten, es ist das Verhältnis zwischen der Leistungsverbesserung des aktuellen Modells gegenüber dem Zufallsmodell und der Leistungsverbesserung des perfekten Modells gegenüber dem Zufallsmodell.
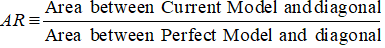
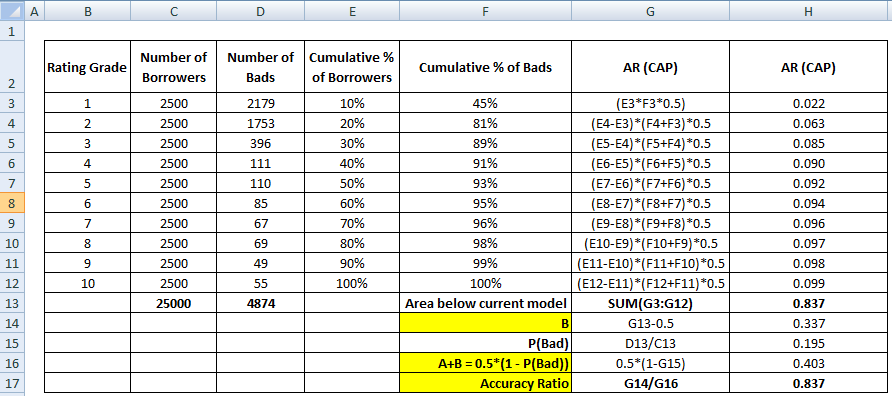
Der erste Schritt ist die Berechnung der Fläche zwischen dem aktuellen Modell und der diagonalen Linie. Wir können die Fläche unter dem aktuellen Modell (einschließlich der Fläche unter der Diagonalen) mit der numerischen Integrationsmethode der Trapezregel berechnen. Die Fläche eines Trapezes ist
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) ist die Breite des Teilintervalls und (yi + yi+1)*0,5 ist die durchschnittliche Höhe.
In diesem Fall bezieht sich x auf die Werte des kumulativen Anteils der Kreditnehmer auf verschiedenen Dezilstufen und y auf den kumulativen Anteil der schlechten Kunden auf verschiedenen Dezilstufen. Der Wert von x0 und y0 ist 0.
Nachdem der obige Schritt abgeschlossen ist, besteht der nächste Schritt darin, 0,5 von der im vorherigen Schritt ermittelten Fläche abzuziehen. Sie werden sich fragen, welche Bedeutung 0,5 hat. Es ist die Fläche unterhalb der diagonalen Linie. Wir subtrahieren, weil wir nur die Fläche zwischen dem aktuellen Modell und der diagonalen Linie benötigen (nennen wir sie B).
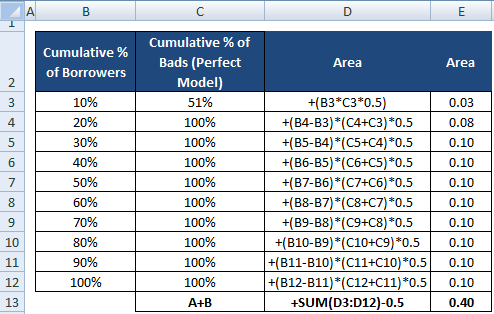
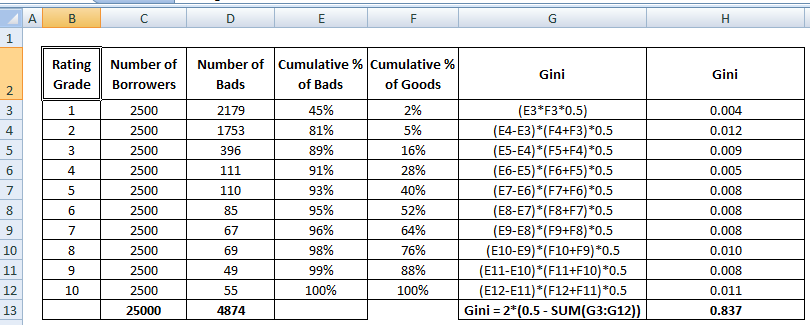
Nun brauchen wir den Nenner, der die Fläche zwischen dem perfekten Modell und der diagonalen Linie ist, A + B. Sie ist gleich 0.5*(1 - Prob(Bad)). Siehe alle Berechnungsschritte in der Tabelle unten –
Der Nenner von AR kann auch so berechnet werden, wie wir die Berechnung für den Zähler durchgeführt haben. Das bedeutet, dass man die Fläche mit „Kumulativer % der Kreditnehmer“ und „Kumulativer % der Schlechten (Perfektes Modell)“ berechnet und dann 0,5 davon abzieht, da wir die Fläche unterhalb der diagonalen Linie nicht berücksichtigen müssen.
Im folgenden R-Code haben wir Beispieldaten für ein Beispiel vorbereitet. Der Variablenname pred bezieht sich auf die vorhergesagten Wahrscheinlichkeiten. Die Variable y bezieht sich auf die abhängige Variable (tatsächliches Ereignis). Wir benötigen nur diese beiden Variablen, um die Accuracy Ratio zu berechnen.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Gini-Koeffizient
Der Gini-Koeffizient ist dem CAP sehr ähnlich, aber er zeigt den Anteil (kumulativ) der guten Kunden anstelle aller Kunden. Er zeigt an, inwieweit das Modell im Vergleich zum Zufallsmodell bessere Klassifizierungsfähigkeiten hat. Er wird auch Gini-Index genannt. Der Gini-Koeffizient kann Werte zwischen -1 und 1 annehmen. Negative Werte entsprechen einem Modell mit umgekehrter Bedeutung der Punktzahlen.
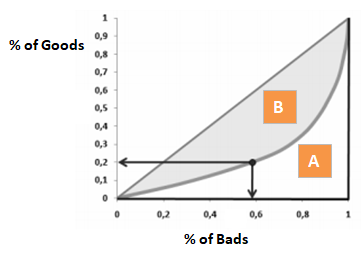
Gini = B / (A+B). Oder Gini = 2B, da der Flächeninhalt von A + B 0,5 ist
Siehe die Berechnungsschritte des Gini-Koeffizienten unten:
Wenn wir x% der guten Kunden ablehnen, welchen Prozentsatz der schlechten Kunden lehnen wir daneben ab.
Der Gini-Koeffizient ist ein Spezialfall der Somerschen D-Statistik. Wenn man Konkordanz- und Diskordanzprozente hat, kann man den Gini-Koeffizienten berechnen.
Gini Coefficient = (Concordance percent - Discordance Percent)Die prozentuale Konkordanz bezieht sich auf den Anteil der Paare, bei denen die Säumigen eine höhere vorhergesagte Wahrscheinlichkeit haben als die guten Kunden.
Die prozentuale Diskordanz bezieht sich auf den Anteil der Paare, bei denen die Säumigen eine geringere vorhergesagte Wahrscheinlichkeit haben als die guten Kunden.
Eine andere Möglichkeit zur Berechnung des Gini-Koeffizienten ist die Verwendung der prozentualen Konkordanz und Diskordanz (wie oben erläutert). Siehe den R-Code unten.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Sind Gini-Koeffizient und Accuracy Ratio gleichwertig?
Ja, sie sind immer gleich. Daher wird der Gini-Koeffizient manchmal auch Accuracy Ratio (AR) genannt.
Ja, ich weiß, dass die Achsen in Gini und AR unterschiedlich sind. Es stellt sich die Frage, wie sie trotzdem gleich sind. Wenn man die Gleichung löst, stellt man fest, dass die Fläche B des Gini-Koeffizienten gleich der Fläche B / Prob(Good) des Accuracy Ratio ist (was gleichbedeutend mit (1/2)*AR ist). Multipliziert man beide Seiten mit 2, erhält man Gini = 2*B und AR = Fläche B / (Fläche A + B)
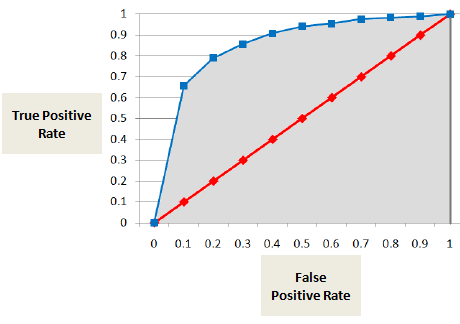
Area under ROC Curve (AUC)
AUC oder ROC-Kurve zeigt den Anteil der wahren Positiven (säumiger Zahler wird korrekt als säumiger Zahler klassifiziert) im Vergleich zum Anteil der falschen Positiven (Nicht-Säumiger wird fälschlicherweise als säumiger Zahler klassifiziert).
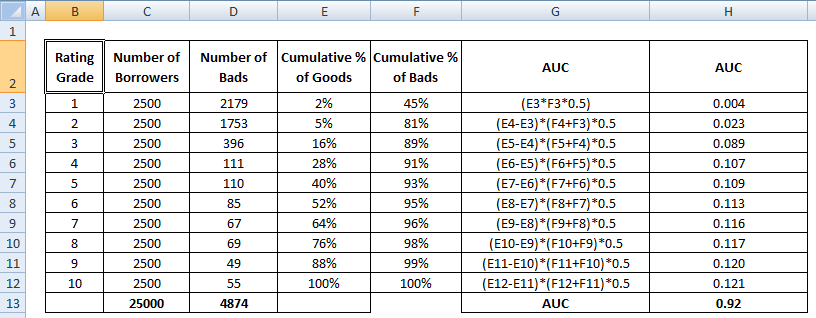
Der AUC-Wert ist die Summe aller Einzelwerte, die auf der Ebene der Ratingstufen oder Dezile berechnet werden.
4 Methoden zur mathematischen Berechnung des AUC
Beziehung zwischen AUC und Gini-Koeffizient
Gini = 2*AUC – 1.
Du fragst dich sicher, wie sie zusammenhängen.
Wenn du die Achse des Diagramms im obigen Abschnitt „Gini-Koeffizient“ umdrehst, erhältst du ein ähnliches Diagramm wie das folgende. Hier Gini = B / (A + B). Die Fläche von A + B ist 0,5, also ist Gini = B / 0,5, was sich zu Gini = 2*B vereinfacht. AUC = B + 0.5, was sich weiter zu B = AUC – 0,5 vereinfacht. Setze diese Gleichung ein Gini = 2*B
Gini = 2*(AUC – 0.5)
Gini = 2*AUC – 1