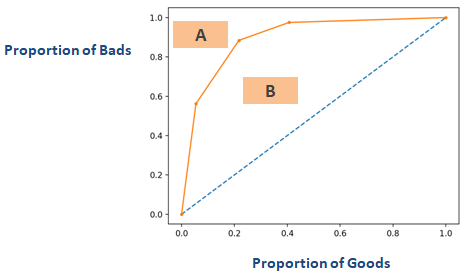
Perfil de Precisión Acumulada (PAC)
El Perfil de Precisión Acumulada (PAC) de un modelo de calificación crediticia muestra el porcentaje de todos los prestatarios (deudores) en el eje x y el porcentaje de morosos (malos clientes) en el eje y. En análisis de marketing, se denominaGain Chart. También se llama Curva de Potencia en algunos otros dominios.
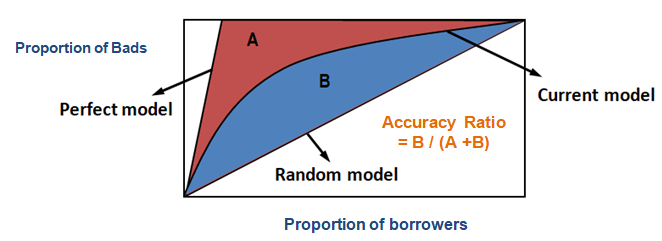
Al utilizar el PAC, puede comparar la curva de su modelo actual con la curva del modelo ‘ideal o perfecto’ y también puede compararla con la curva del modelo aleatorio. ‘Modelo perfecto’ se refiere al estado ideal en el que todos los malos clientes (resultado deseado) pueden ser capturados directamente. El ‘modelo aleatorio’ se refiere al estado en el que la proporción de malos clientes se distribuye por igual. El ‘modelo actual’ se refiere a su modelo de probabilidad de impago (o cualquier otro modelo en el que esté trabajando). Siempre intentamos construir el modelo que se inclina hacia (más cerca) la curva del modelo perfecto. Podemos leer el modelo actual como ‘% de clientes malos cubiertos en un nivel de decil determinado’. Por ejemplo, el 89% de los malos clientes capturados sólo seleccionando el 30% superior de los deudores basados en el modelo.
- Ordenar la probabilidad estimada de impago en orden descendente y dividirla en 10 partes (decil). Esto significa que los prestatarios más arriesgados con una alta PD deberían estar en el decil superior y los más seguros deberían aparecer en el decil inferior. Dividir la puntuación en 10 partes no es una regla general. En su lugar se puede utilizar el grado de calificación.
- Calcular el número de prestatarios (observaciones) en cada decil
- Calcular el número de clientes malos en cada decil
- Calcular el número acumulado de clientes malos en cada decil
- Calcular porcentaje de clientes malos en cada decil
- Calcular porcentaje acumulado de clientes malos en cada decil
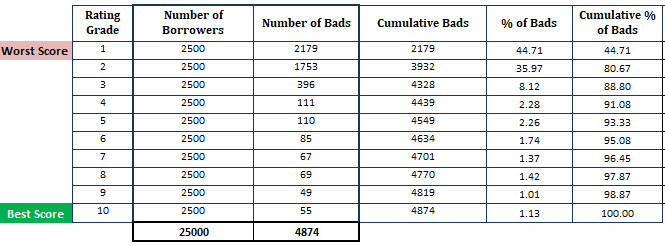
Hasta ahora, hemos hecho el cálculo basado en el modelo PD (Recuerde que el primer paso se basa en las probabilidades obtenidas del modelo PD).
Siguiente paso: ¿Cuál debería ser el número de clientes malos en cada decil basado en el modelo perfecto?
- En el modelo perfecto, el primer decil debería capturar a todos los clientes malos ya que el primer decil se refiere al peor grado de calificación O a los prestatarios con mayor probabilidad de impago. En nuestro caso, el primer decil no puede capturar a todos los clientes malos ya que el número de prestatarios que caen en el primer decil es menor que el número total de clientes malos.
- Calcule el número acumulado de clientes malos en cada decil basándose en el modelo perfecto
- Calcule el % acumulado de clientes malos en cada decil basándose en el modelo perfecto

Próximo paso: Calcule el porcentaje acumulado de clientes malos en cada decil basándose en el modelo aleatorioEn el modelo aleatorio, cada decil debe constituir el 10%. Cuando calculemos el porcentaje acumulado, será el 10% en el decil 1, el 20% en el decil 2 y así sucesivamente hasta el 100% en el decil 10.
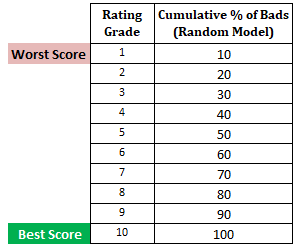
Próximo paso : Crear un gráfico con el porcentaje acumulado de malos basado en el modelo actual, aleatorio y perfecto. En el eje x, se muestra el porcentaje de prestatarios (observaciones) y el eje y representa el porcentaje de clientes malos.
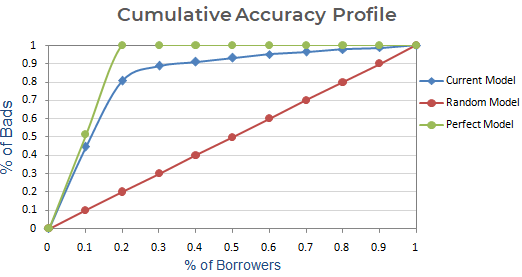
Relación de exactitud
En el caso del PAC (Perfil de exactitud acumulativo), la relación de exactitud es la relación del área entre su modelo predictivo actual y la línea diagonal y el área entre el modelo perfecto y la línea diagonal. En otras palabras, es la relación entre la mejora del rendimiento del modelo actual sobre el modelo aleatorio y la mejora del rendimiento del modelo perfecto sobre el modelo aleatorio.
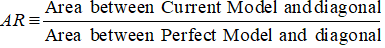
El primer paso es calcular el área entre el modelo actual y la línea diagonal. Podemos calcular el área bajo el modelo actual (incluyendo el área bajo la línea diagonal) utilizando el método de integración numérica de la regla trapezoidal. El área de un trapezoide es
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) es la anchura del subintervalo y (yi + yi+1)*0,5 es la altura media.
En este caso, x se refiere a los valores de la proporción acumulada de prestatarios en los diferentes niveles de decil e y se refiere a la proporción acumulada de clientes malos en los diferentes niveles de decil. El valor de x0 e y0 es 0.
Una vez completado el paso anterior, el siguiente paso es restar 0,5 del área obtenida en el paso anterior. Usted debe preguntarse relevancia de 0,5. Es el área por debajo de la línea diagonal. Estamos restando porque sólo necesitamos el área entre el modelo actual y la línea diagonal (llamémosla B).
Ahora necesitamos el denominador que es el área entre el modelo perfecto y la línea diagonal, A + B. Equivale a 0.5*(1 - Prob(Bad)). Vea todos los pasos de cálculo que se muestran en la tabla siguiente –
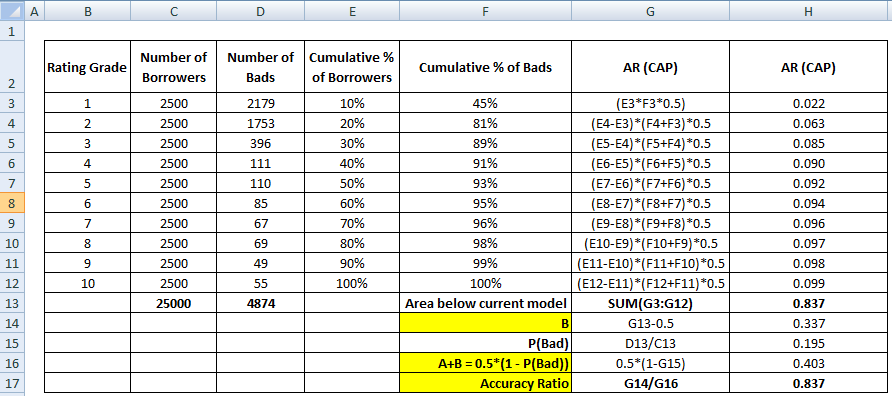
El denominador de AR también se puede calcular como hemos realizado el cálculo para el numerador. Significa calcular el área utilizando el «% acumulativo de prestatarios» y el «% acumulativo de malos (modelo perfecto)» y luego restarle 0,5 ya que no necesitamos considerar el área por debajo de la línea diagonal.
En el código R a continuación, preparamos datos de muestra para el ejemplo. El nombre de la variable pred se refiere a las probabilidades predichas. La variable y se refiere a la variable dependiente (evento real). Sólo necesitamos estas dos variables para calcular el Ratio de Precisión.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Coeficiente de Gini
El coeficiente de Gini es muy similar al CAP pero muestra la proporción (acumulada) de buenos clientes en lugar de todos los clientes. Muestra hasta qué punto el modelo tiene una mejor capacidad de clasificación en comparación con el modelo aleatorio. También se denomina índice de Gini. El Coeficiente de Gini puede tomar valores entre -1 y 1. Los valores negativos corresponden a un modelo con significados invertidos de las puntuaciones.
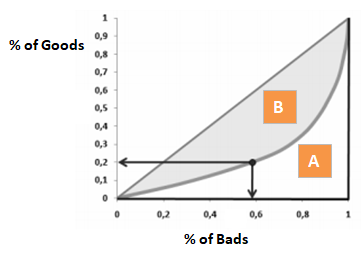
Gini = B / (A+B). O Gini = 2B ya que el Área de A + B es 0,5
Vea los pasos de cálculo del Coeficiente de Gini a continuación :
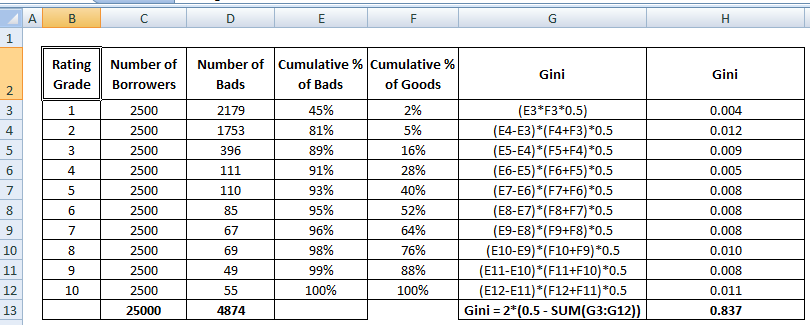
Al rechazar el x% de los buenos clientes, qué porcentaje de malos clientes rechazamos al lado.
El coeficiente de Gini es un caso especial de la estadística D de Somer. Si tienes porcentaje de concordancia y discordancia, puedes calcular el Coeficiente de Gini.
Gini Coefficient = (Concordance percent - Discordance Percent)El porcentaje de concordancia se refiere a la proporción de pares en los que los morosos tienen una mayor probabilidad prevista que los buenos clientes.
El porcentaje de discordancia se refiere a la proporción de pares en los que los morosos tienen una menor probabilidad prevista que los buenos clientes.
Otra forma de calcular el Coeficiente de Gini es utilizando el porcentaje de concordancia y discordancia (como se ha explicado anteriormente). Consulte el código R que aparece a continuación.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
¿Son equivalentes el Coeficiente de Gini y el Coeficiente de Precisión?
Sí, siempre son iguales. Por lo tanto, el Coeficiente de Gini a veces se denomina Ratio de Precisión (AR).
Sí, sé que los ejes de Gini y AR son diferentes. La pregunta que surge es cómo siguen siendo iguales. Si resuelve la ecuación, encontrará que el Área B en el Coeficiente de Gini es la misma que el Área B / Prob(Good) en el Ratio de Precisión (que equivale a (1/2)*AR ). Multiplicando ambos lados por 2, obtendrá Gini = 2*B y AR = Área B / (Área A + B)
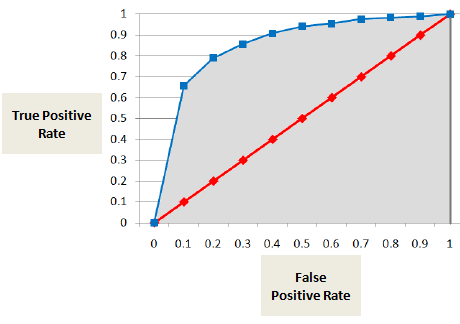
Área bajo la Curva ROC (AUC)
El AUC o curva ROC muestra la proporción de verdaderos positivos (el moroso se clasifica correctamente como moroso) frente a la proporción de falsos positivos (el no moroso se clasifica erróneamente como moroso).
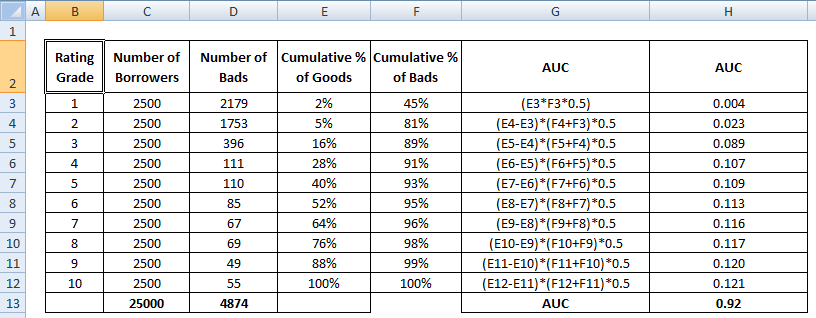
La puntuación del AUC es la suma de todos los valores individuales calculados a nivel de grado de calificación o decil.
4 Métodos para calcular el AUC Matemáticamente
Relación entre el AUC y el Coeficiente de Gini
Gini = 2*AUC – 1.
Se debe estar preguntando cómo se relacionan.
Si se invierte el eje de la gráfica mostrada en la sección anterior llamada «Coeficiente de Gini», se obtendría algo similar a la gráfica siguiente. Aquí Gini = B / (A + B). El área de A + B es 0,5 por lo que Gini = B / 0,5 que se simplifica a Gini = 2*B. AUC = B + 0.5 que se simplifica aún más a B = AUC – 0,5. Ponga esta ecuación en Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1