Profil de précision cumulatif (PAC)
Le profil de précision cumulatif (PAC) d’un modèle de notation de crédit montre le pourcentage de tous les emprunteurs (débiteurs) sur l’axe des abscisses et le pourcentage de mauvais payeurs (mauvais clients) sur l’axe des ordonnées. En analyse marketing, elle est appeléeGain Chart. Elle est également appelée Courbe de puissance dans certains autres domaines.
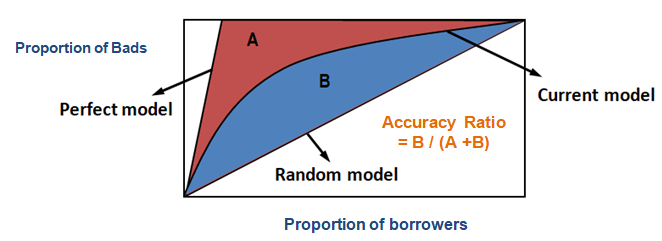
En utilisant CAP, vous pouvez comparer la courbe de votre modèle actuel à la courbe du modèle ‘idéal ou parfait’ et vous pouvez également la comparer à la courbe du modèle aléatoire. Le ‘modèle parfait’ fait référence à l’état idéal dans lequel tous les mauvais clients (résultat souhaité) peuvent être capturés directement. Le « modèle aléatoire » fait référence à l’état dans lequel la proportion de mauvais clients est distribuée de manière égale. Le « modèle actuel » fait référence à votre modèle de probabilité de défaut (ou tout autre modèle sur lequel vous travaillez). Nous essayons toujours de construire le modèle qui se rapproche le plus de la courbe du modèle parfait. Nous pouvons lire le modèle actuel comme « % de mauvais clients couverts à un niveau de décile donné ». Par exemple, 89 % des mauvais clients capturés en sélectionnant simplement les 30 % de débiteurs les plus élevés sur la base du modèle.
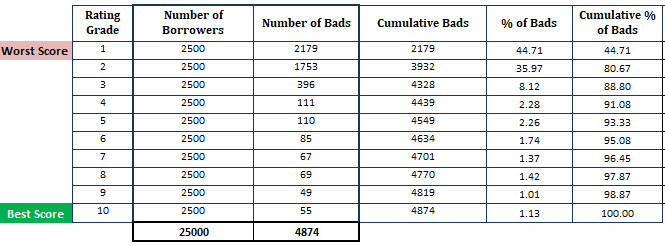
- Trier la probabilité de défaut estimée par ordre décroissant et la diviser en 10 parties (décile). Cela signifie que les emprunteurs les plus risqués avec une PD élevée devraient se trouver dans le décile supérieur et les emprunteurs les plus sûrs devraient apparaître dans le décile inférieur. La division du score en 10 parties n’est pas une règle empirique. Au lieu de cela, vous pouvez utiliser le grade de notation.
- Calculer le nombre d’emprunteurs (observations) dans chaque décile
- Calculer le nombre de mauvais clients dans chaque décile
- Calculer le nombre cumulé de mauvais clients dans chaque décile
- Calculer le pourcentage de mauvais clients dans chaque décile
- Calculer le pourcentage cumulé de mauvais clients dans chaque décile
.
Jusqu’à présent, nous avons fait un calcul basé sur le modèle PD (Rappelez-vous que la première étape est basée sur les probabilités obtenues à partir du modèle PD).
Étape suivante : Quel devrait être le nombre de mauvais clients dans chaque décile sur la base du modèle parfait ?
- Dans le modèle parfait, le premier décile devrait capturer tous les mauvais clients car le premier décile se réfère à la pire note OU aux emprunteurs avec la plus grande probabilité de défaut. Dans notre cas, le premier décile ne peut pas capturer tous les mauvais clients car le nombre d’emprunteurs tombant dans le premier décile est inférieur au nombre total de mauvais clients.
- Calculer le nombre cumulé de mauvais clients dans chaque décile en fonction du modèle parfait
- Calculer le % cumulé de mauvais clients dans chaque décile en fonction du modèle parfait

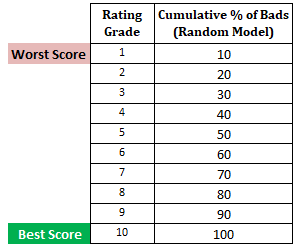
Étape suivante : Calculer le pourcentage cumulé de mauvais clients dans chaque décile en fonction du modèle aléatoireDans le modèle aléatoire, chaque décile doit constituer 10%. Lorsque nous calculons le % cumulé, il sera de 10% dans le décile 1, 20% dans le décile 2 et ainsi de suite jusqu’à 100% dans le décile 10.
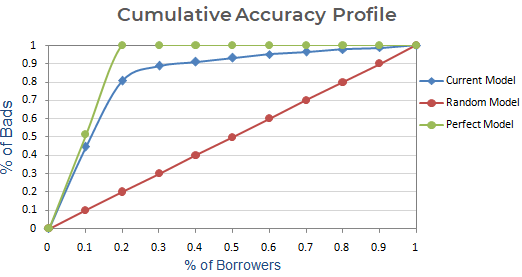
Étape suivante : Créer un graphique avec le % cumulé de mauvais en fonction du modèle actuel, aléatoire et parfait. En axe x, il montre le pourcentage d’emprunteurs (observations) et l’axe y représente le pourcentage de mauvais clients.
Ratio d’exactitude
Dans le cas du CAP (profil d’exactitude cumulatif), le ratio d’exactitude est le rapport de la zone entre votre modèle prédictif actuel et la ligne diagonale et la zone entre le modèle parfait et la ligne diagonale. En d’autres termes, c’est le rapport entre l’amélioration des performances du modèle actuel par rapport au modèle aléatoire et l’amélioration des performances du modèle parfait par rapport au modèle aléatoire.
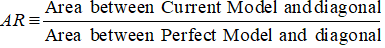
La première étape consiste à calculer la zone entre le modèle actuel et la ligne diagonale. Nous pouvons calculer l’aire sous le modèle actuel (y compris l’aire sous la ligne diagonale) en utilisant la méthode d’intégration numérique de la règle trapézoïdale. L’aire d’un trapèze est
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) est la largeur du sous-intervalle et (yi + yi+1)*0,5 est la hauteur moyenne.
Dans ce cas, x fait référence aux valeurs de la proportion cumulée d’emprunteurs à différents niveaux de décile et y fait référence à la proportion cumulée de mauvais clients à différents niveaux de décile. La valeur de x0 et y0 est 0.
Une fois l’étape ci-dessus terminée, l’étape suivante consiste à soustraire 0,5 de la surface renvoyée par l’étape précédente. Vous devez vous demander quelle est la pertinence de 0,5. Il s’agit de la zone située sous la ligne diagonale. Nous soustrayons parce que nous avons seulement besoin de la zone entre le modèle actuel et la ligne diagonale (appelons-la B).
Maintenant nous avons besoin du dénominateur qui est la zone entre le modèle parfait et la ligne diagonale, A + B. Elle est équivalente à 0.5*(1 - Prob(Bad)). Voir toutes les étapes de calcul indiquées dans le tableau ci-dessous –
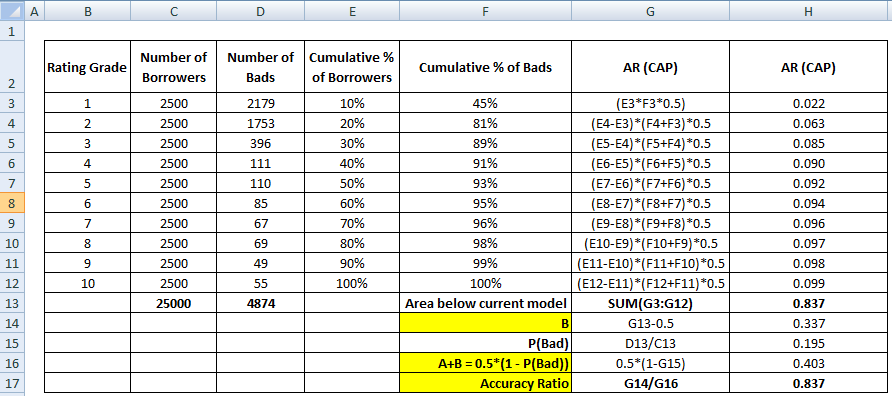
Le dénominateur du RA peut également être calculé comme nous avons effectué le calcul pour le numérateur. Cela signifie calculer la zone en utilisant le « % cumulé d’emprunteurs » et le « % cumulé de mauvais (modèle parfait) », puis en soustraire 0,5 puisque nous n’avons pas besoin de considérer la zone sous la ligne diagonale.
Dans le code R ci-dessous, nous avons préparé des données d’échantillon pour l’exemple. Le nom de la variable pred fait référence aux probabilités prédites. La variable y fait référence à la variable dépendante (événement réel). Nous n’avons besoin que de ces deux variables pour calculer le ratio de précision.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Coefficient de Gini
Le coefficient de Gini est très similaire au CAP mais il montre la proportion (cumulative) de bons clients au lieu de tous les clients. Il montre dans quelle mesure le modèle a de meilleures capacités de classification par rapport au modèle aléatoire. Il est également appelé indice de Gini. Le coefficient de Gini peut prendre des valeurs entre -1 et 1. Les valeurs négatives correspondent à un modèle avec des significations inversées des scores.
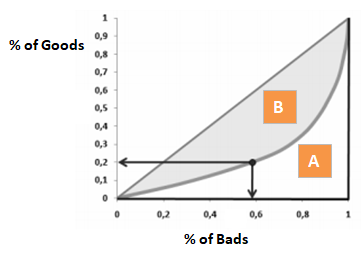
Gini = B / (A+B). Ou Gini = 2B puisque l’aire de A + B est de 0,5
Voir les étapes de calcul du coefficient de Gini ci-dessous :
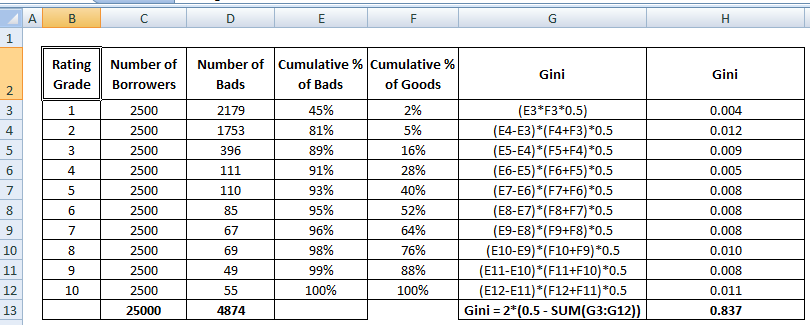
En rejetant x% de bons clients, quel pourcentage de mauvais clients nous rejetons à côté.
Le coefficient de Gini est un cas particulier de la statistique D de Somer. Si vous avez le pourcentage de concordance et de discordance, vous pouvez calculer le coefficient de Gini.
Gini Coefficient = (Concordance percent - Discordance Percent)Le pourcentage de concordance fait référence à la proportion de paires où les défaillants ont une probabilité prédite plus élevée que les bons clients.
Le pourcentage de discordance fait référence à la proportion de paires où les défaillants ont une probabilité prédite plus faible que les bons clients.
Une autre façon de calculer le coefficient de Gini consiste à utiliser la concordance et le pourcentage de discordance (comme expliqué ci-dessus). Reportez-vous au code R ci-dessous.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Le coefficient de Gini et le rapport de précision sont-ils équivalents ?
Oui, ils sont toujours égaux. Par conséquent, le coefficient de Gini est parfois appelé ratio de précision (AR).
Oui, je sais que les axes dans Gini et AR sont différents. La question se pose de savoir comment ils sont toujours les mêmes. Si vous résolvez l’équation, vous trouverez que la zone B dans le coefficient de Gini est la même que la zone B / Prob(Good) dans le ratio de précision (qui est équivalent à (1/2)*AR ). En multipliant les deux côtés par 2, vous obtiendrez Gini = 2*B et AR = Zone B / (Zone A + B)
Aire sous la courbe ROC (AUC)
L’AUC ou la courbe ROC montre la proportion de vrais positifs (le défaillant est correctement classé comme défaillant) par rapport à la proportion de faux positifs (le non défaillant est classé à tort comme défaillant).
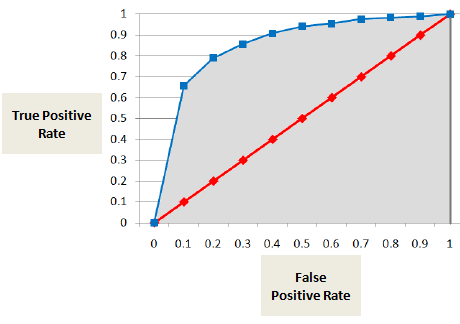
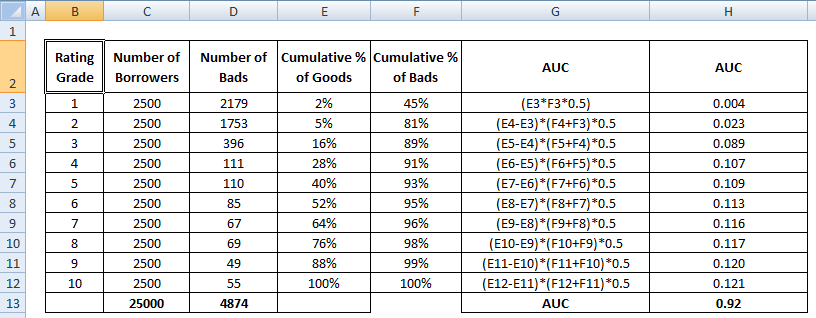
Le score de l’AUC est la somme de toutes les valeurs individuelles calculées au niveau de la classe de classement ou du décile.
4 Méthodes pour calculer l’AUC Mathématiquement
Relation entre l’AUC et le coefficient de Gini
Gini = 2*AUC – 1.
Vous devez vous demander comment ils sont liés.
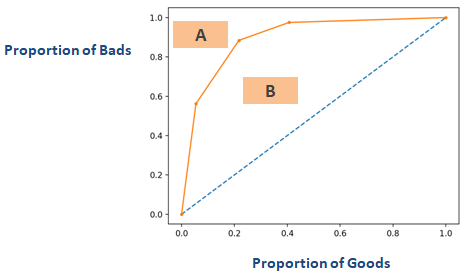
Si vous inversez l’axe du graphique présenté dans la section ci-dessus nommée « Coefficient de Gini », vous obtiendrez un graphique similaire à celui ci-dessous. Ici Gini = B / (A + B). L’aire de A + B est de 0,5, donc Gini = B / 0,5 qui se simplifie en Gini = 2*B. AUC = B + 0.5 qui se simplifie encore en B = AUC – 0.5. Mettez cette équation dans Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1
.