Kumulatiivinen tarkkuusprofiili (CAP)
Luottoluokitusmallin kumulatiivinen tarkkuusprofiili (CAP) osoittaa x-akselilla kaikkien lainanottajien (velallisten) prosenttiosuuden ja y-akselilla maksukyvyttömien (huonojen asiakkaiden) prosenttiosuuden. Markkinointianalytiikassa sitä kutsutaanGain Chart. Joillakin muilla aloilla sitä kutsutaan myös tehokäyräksi.
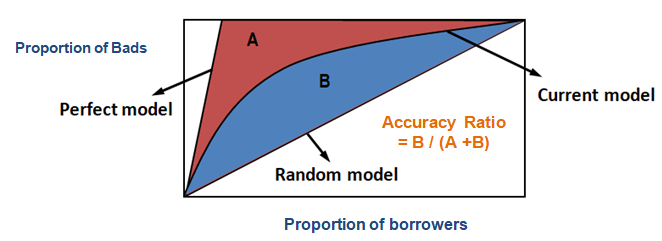
Käyttämällä CAP:ia voit verrata nykyisen mallisi käyrää ”ihanteellisen tai täydellisen” mallin käyrään ja voit myös verrata sitä satunnaisen mallin käyrään. ’Täydellisellä mallilla’ tarkoitetaan ideaalitilaa, jossa kaikki huonot asiakkaat (haluttu lopputulos) voidaan vangita suoraan. ’Satunnaismalli’ viittaa tilaan, jossa huonojen asiakkaiden osuus jakautuu tasaisesti. ’Nykyinen malli’ tarkoittaa maksuhäiriöiden todennäköisyysmallia (tai mitä tahansa muuta mallia, jonka parissa työskentelet). Pyrimme aina rakentamaan mallin, joka nojaa kohti (lähemmäs) täydellisen mallin käyrää. Nykyinen malli voidaan tulkita muodossa ”% huonoista asiakkaista, jotka on katettu tietyllä desiilitasolla”. Esimerkiksi 89 % huonoista asiakkaista katetaan valitsemalla mallin perusteella vain 30 % velallisista.
- Lajittele arvioitu maksukyvyttömyyden todennäköisyys alenevaan järjestykseen ja jaa se 10 osaan (desiiliin). Se tarkoittaa, että riskialttiimpien lainanottajien, joilla on korkea PD, pitäisi olla ylimmässä desiilissä ja turvallisimpien lainanottajien pitäisi olla alimmassa desiilissä. Pisteiden jakaminen 10 osaan ei ole peukalosääntö. Sen sijaan voit käyttää luokitusluokkaa.
- Lasketaan lainanottajien (havaintojen) lukumäärä kussakin desiilissä
- Lasketaan huonojen asiakkaiden lukumäärä kussakin desiilissä
- Lasketaan huonojen asiakkaiden kumulatiivinen lukumäärä kussakin desiilissä
- Lasketaan huonojen asiakkaiden prosenttiosuus kussakin desiilissä
- Lasketaan huonojen asiakkaiden kumulatiivinen prosenttiosuus kussakin desiilissä
.
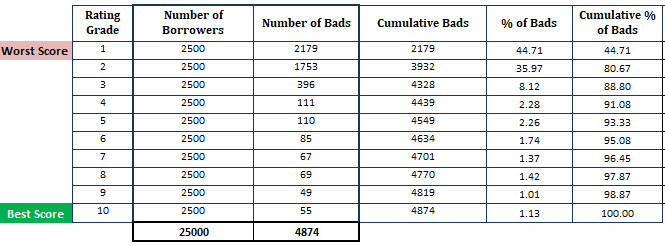
Tänään, olemme tehneet laskelman PD-mallin perusteella (Muista, että ensimmäinen vaihe perustuu PD-mallista saatuihin todennäköisyyksiin).
Seuraava vaihe: Kuinka monta huonoa asiakasta kussakin desiilissä pitäisi olla täydellisen mallin perusteella?
- Täydellisessä mallissa ensimmäisen desiilin pitäisi kattaa kaikki huonot asiakkaat, koska ensimmäinen desiili viittaa huonoimpaan luottoluokkaan TAI lainanottajiin, joilla on korkein maksukyvyttömyyden todennäköisyys. Meidän tapauksessamme ensimmäinen desiili ei voi kattaa kaikkia huonoja asiakkaita, koska ensimmäiseen desiiliin kuuluvien lainanottajien määrä on pienempi kuin huonojen asiakkaiden kokonaismäärä.
- Lasketaan kussakin desiilissä olevien huonojen asiakkaiden kumulatiivinen määrä täydellisen mallin perusteella
- Lasketaan kussakin desiilissä olevien huonojen asiakkaiden kumulatiivinen prosenttiosuus täydellisen mallin perusteella

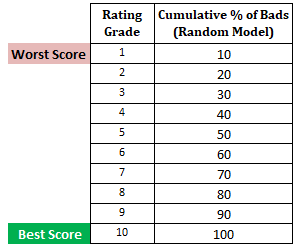
Jatkovaihe: Lasketaan kussakin desiilissä olevien huonojen asiakkaiden kumulatiivinen prosenttiosuus satunnaismallin perusteellaSatunnaismallissa kunkin desiilin tulisi muodostaa 10 %. Kun laskemme kumulatiivisen %:n, se on 10 % desiilissä 1, 20 % desiilissä 2 ja niin edelleen, kunnes se on 100 % desiilissä 10.
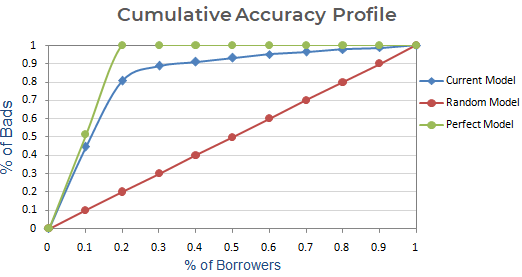
Jatkovaihe : Luo kaavio, jossa esitetään huonojen asiakkaiden kumulatiivinen % nykyisen, satunnaisen ja täydellisen mallin perusteella. x-akselilla se osoittaa lainanottajien (havaintojen) prosenttiosuuden ja y-akselilla huonojen asiakkaiden prosenttiosuuden.
Tarkkuussuhde
Kumulatiivisen tarkkuusprofiilin (CAP, Cumulative Accuracy Profile) tapauksessa tarkkuussuhde on nykyisen ennustemallisi ja diagonaaliviivan välisen alueen ja täydellisen mallin ja diagonaaliviivan välisen alueen suhde. Toisin sanoen se on nykyisen mallin suorituskyvyn paranemisen suhde satunnaismalliin verrattuna täydellisen mallin suorituskyvyn paranemiseen satunnaismalliin verrattuna.
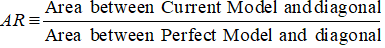
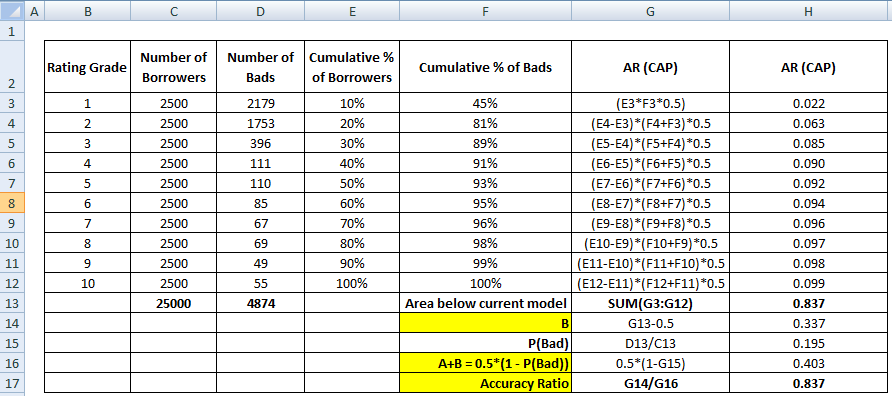
Ensimmäinen vaihe on laskea nykyisen mallin ja diagonaaliviivan välinen alue. Voimme laskea nykyisen mallin alapuolella olevan pinta-alan (mukaan lukien diagonaaliviivan alapuolella oleva pinta-ala) käyttämällä Trapezoidal Rule Numerical Integration -menetelmää. Trapetsin pinta-ala on
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) on osavälien leveys ja (yi + yi+1)*0,5 on keskimääräinen korkeus.
Tässä tapauksessa x viittaa lainanottajien kumulatiivisen osuuden arvoihin eri desiilitasoilla ja y viittaa huonojen asiakkaiden kumulatiiviseen osuuteen eri desiilitasoilla. x0:n ja y0:n arvo on 0.
Kun edellä mainittu vaihe on suoritettu, seuraava vaihe on vähentää 0,5 edellisestä vaiheesta palautetusta pinta-alasta. Sinun täytyy miettiä 0,5:n merkitystä. Se on diagonaaliviivan alapuolella oleva alue. Vähennämme sen, koska tarvitsemme vain nykyisen mallin ja diagonaaliviivan välisen alueen (kutsutaan sitä B).
Nyt tarvitsemme nimittäjän, joka on täydellisen mallin ja diagonaaliviivan välinen alue, A + B. Se vastaa 0.5*(1 - Prob(Bad)). Katso kaikki laskentavaiheet alla olevasta taulukosta –
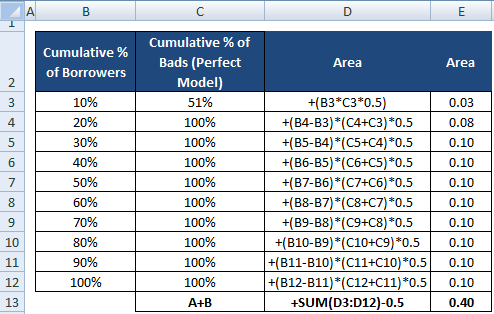
Tarkkuussuhteen nimittäjä voidaan myös laskea, kuten suoritimme laskennan osoittajalle. Se tarkoittaa alueen laskemista käyttämällä ”Lainanottajien kumulatiivista %:a” ja ”Huonojen kumulatiivista %:a (Täydellinen malli)” ja vähentämällä siitä sitten 0,5, koska meidän ei tarvitse ottaa huomioon diagonaaliviivan alapuolella olevaa aluetta.
Alla olevassa R-koodissa olemme valmistelleet esimerkkidataa. Muuttujan nimi pred viittaa ennustettuihin todennäköisyyksiin. Muuttuja y viittaa riippuvaiseen muuttujaan (todellinen tapahtuma). Tarvitsemme vain näitä kahta muuttujaa laskeaksemme Accuracy Ratio.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
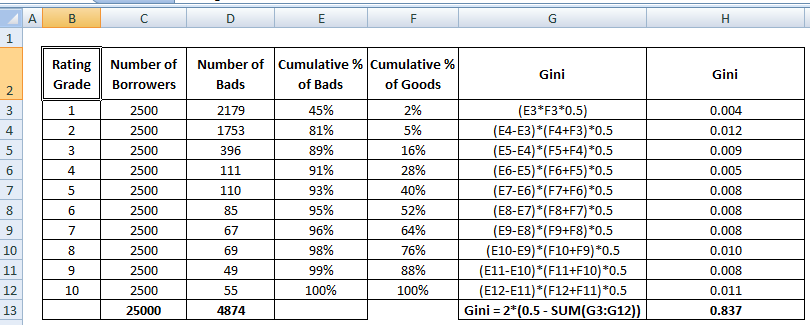
Gini-kerroin
Gini-kerroin on hyvin samankaltainen kuin CAP, mutta se osoittaa kaikkien asiakkaiden sijasta hyvien asiakkaiden osuuden (kumulatiivisen). Se osoittaa, missä määrin mallilla on paremmat luokittelukyvyt satunnaismalliin verrattuna. Sitä kutsutaan myös Gini-indeksiksi. Gini-kerroin voi saada arvoja välillä -1 ja 1. Negatiiviset arvot vastaavat mallia, jossa pisteiden merkitys on käänteinen.
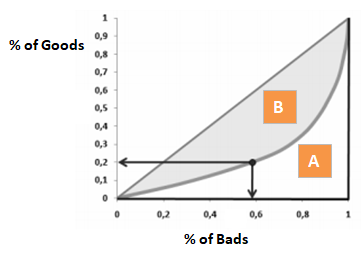
Gini = B / (A+B). Tai Gini = 2B, koska A + B:n pinta-ala on 0,5
Katso Gini-kertoimen laskentavaiheet alla :
Hylkäämällä x % hyvistä asiakkaista, minkä prosenttiosuuden huonoja asiakkaita hylkäämme rinnalla.
Gini-kerroin on Somerin D-tilaston erikoistapaus. Jos sinulla on konkordanssi- ja diskordanssiprosentti, voit laskea Gini-kertoimen.
Gini Coefficient = (Concordance percent - Discordance Percent)Konkordanssiprosentti tarkoittaa niiden parien osuutta, joissa hylkääjillä on suurempi ennustettu todennäköisyys kuin hyvillä asiakkailla.
Diskordanssiprosentti tarkoittaa niiden parien osuutta, joissa hylkääjillä on pienempi ennustettu todennäköisyys kuin hyvillä asiakkailla.
Toinen tapa laskea Gini-kerroin on käyttää konkordanssi- ja diskordanssiprosenttia (kuten edellä on selitetty). Katso alla oleva R-koodi.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Ovatko Gini-kerroin ja Accuracy Ratio samanarvoisia?
Kyllä, ne ovat aina samanarvoisia. Näin ollen Gini-kerrointa kutsutaan joskus nimellä Accuracy Ratio (AR).
Kyllä, tiedän, että Gini- ja AR-kertoimen akselit ovat erilaiset. Herää kysymys, miten ne ovat silti samat. Jos ratkaiset yhtälön, huomaat, että pinta-ala B Gini-kertoimessa on sama kuin pinta-ala B / Prob(Good) Accuracy Ratio (joka vastaa (1/2)*AR ). Kun molemmat puolet kerrotaan kahdella, saadaan Gini = 2*B ja AR = Area B / (Area A + B)
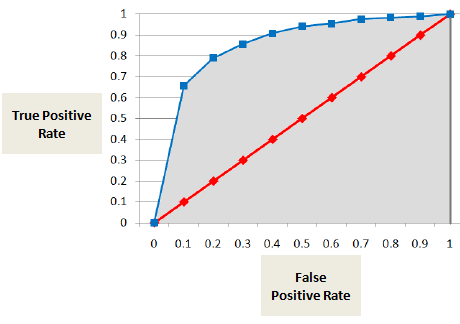
Area under ROC Curve (AUC)
AUC tai ROC-käyrä osoittaa oikeiden positiivisten tulosten osuuden (maksukyvytön luokitellaan oikein maksukyvyttömäksi) verrattuna väärien positiivisten tulosten osuuteen (maksukyvytön luokitellaan virheellisesti maksukyvyttömäksi).
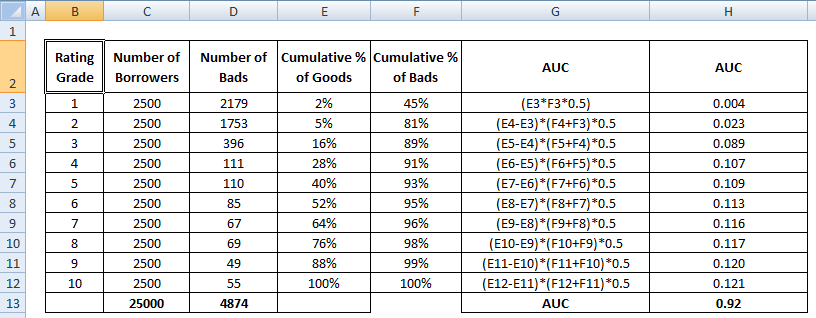
AUC-pistemäärä on kaikkien luokitusluokka- tai desiilitasolla laskettujen yksittäisten arvojen summa.
4 AUC:n laskentamenetelmät Matemaattisesti
AUC:n ja Gini-kertoimen välinen suhde
Gini = 2*AUC – 1.
Voit varmaan ihmetellä, miten ne liittyvät toisiinsa.
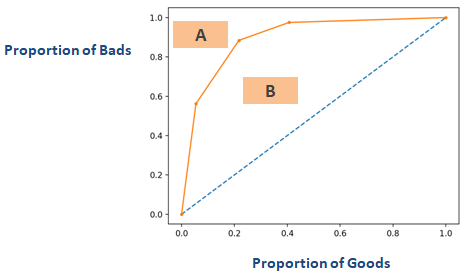
Jos käännät edellä olevassa osiossa ”Gini-kerroin” nimetyn kaavion akselin toisin päin, saat samanlaisen kuin alla oleva kaavio. Tässä Gini = B / (A + B). A + B:n pinta-ala on 0,5, joten Gini = B / 0,5, joka yksinkertaistettuna on Gini = 2*B. AUC = B + 0.5, joka edelleen yksinkertaistuu muotoon B = AUC – 0.5. Laitetaan tämä yhtälö Gini = 2*B
Gini = 2*(AUC – 0.5)
Gini = 2*AUC – 1
.