Kumulatív pontossági profil (CAP)
A hitelminősítő modell kumulatív pontossági profilja (CAP) az összes hitelfelvevő (adós) százalékos arányát mutatja az x tengelyen és a nem fizetők (rossz ügyfelek) százalékos arányát az y tengelyen. A marketinganalitikában eztGain Chart-nak nevezik. Néhány más területen teljesítménygörbének is nevezik.
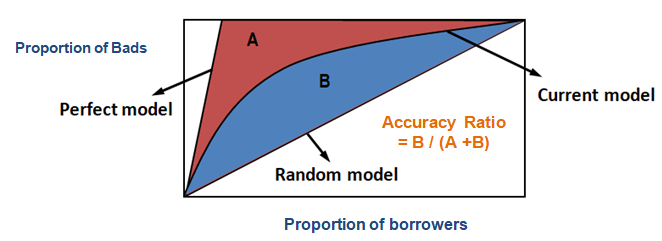
A CAP segítségével összehasonlíthatja a jelenlegi modell görbéjét az “ideális vagy tökéletes” modell görbéjével, és összehasonlíthatja a véletlenszerű modell görbéjével is. A ‘tökéletes modell’ az ideális állapotra utal, amelyben az összes rossz ügyfél (kívánt eredmény) közvetlenül megragadható. A “véletlen modell” arra az állapotra utal, amelyben a rossz ügyfelek aránya egyenletesen oszlik el. A “jelenlegi modell” az Ön nemteljesítési valószínűségi modelljére (vagy bármely más modellre, amelyen dolgozik) utal. Mindig azt a modellt igyekszünk megalkotni, amelyik a tökéletes modell görbéje felé hajlik (közelebb). Az aktuális modellt úgy is olvashatjuk, mint “a rossz ügyfelek adott tizedes szinten lefedett %-ának”. Például a rossz ügyfelek 89%-a lefedett, ha a modell alapján csak az adósok felső 30%-át választjuk ki.
- A nemfizetés becsült valószínűségét csökkenő sorrendbe rendezzük, és 10 részre (tizedre) osztjuk. Ez azt jelenti, hogy a legkockázatosabb, magas PD-vel rendelkező hitelfelvevőknek a felső tizedben, a legbiztonságosabb hitelfelvevőknek pedig az alsó tizedben kell megjelenniük. A pontszám 10 részre osztása nem egy hüvelykujjszabály. Ehelyett használhatja a minősítési fokozatot.
- A hitelfelvevők (megfigyelések) számának kiszámítása az egyes tizedekben
- A rossz ügyfelek számának kiszámítása az egyes tizedekben
- A rossz ügyfelek kumulatív számának kiszámítása az egyes tizedekben
- A rossz ügyfelek százalékos arányának kiszámítása minden egyes tizedben
- A rossz ügyfelek kumulatív százalékos arányának kiszámítása minden egyes tizedben
.
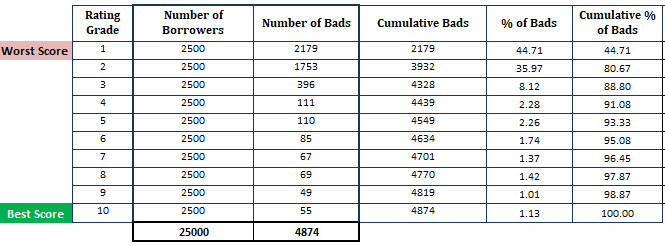
Most, a PD-modell alapján végeztük a számításokat (ne feledje, hogy az első lépés a PD-modellből kapott valószínűségeken alapul).
Következő lépés : Mennyi legyen a rossz ügyfelek száma az egyes tizedekben a tökéletes modell alapján?
- A tökéletes modellben az első tizednek az összes rossz ügyfelet meg kell ragadnia, mivel az első tized a legrosszabb minősítési osztályra utal, VAGY a legnagyobb valószínűséggel nem teljesítő hitelfelvevőkre. A mi esetünkben az első tized nem képes az összes rossz ügyfelet megragadni, mivel az első tizedbe tartozó hitelfelvevők száma kevesebb, mint a rossz ügyfelek teljes száma.
- A rossz ügyfelek kumulatív számának kiszámítása minden egyes tizedben a tökéletes modell alapján
- A rossz ügyfelek kumulatív %-ának kiszámítása minden egyes tizedben a tökéletes modell alapján

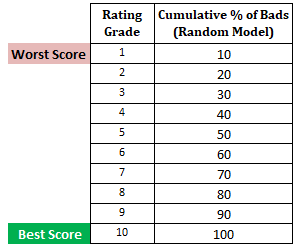
Következő lépés : A rossz ügyfelek kumulatív százalékos arányának kiszámítása minden egyes tizedben a véletlen modell alapjánA véletlen modellben minden tizednek 10%-ot kell kitennie. Amikor kiszámítjuk a kumulatív %-ot, az 1. tizedben 10%, a 2. tizedben 20%, és így tovább a 10. tizedben 100%-ig.
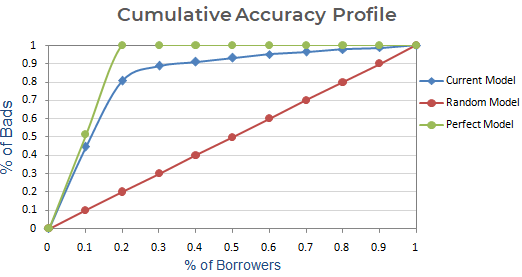
Következő lépés : Készítsünk egy ábrát a rossz ügyfelek kumulatív %-ával a jelenlegi, a véletlen és a tökéletes modell alapján. Az x tengelyen a hitelfelvevők (megfigyelések) százalékos arányát, az y tengelyen pedig a Rossz ügyfelek százalékos arányát mutatja.
A pontossági arány
A CAP (Kumulatív pontossági profil) esetében a pontossági arány a jelenlegi előrejelző modellje és az átlós vonal közötti terület és a tökéletes modell és az átlós vonal közötti terület aránya. Más szóval, ez az aktuális modell véletlen modellhez viszonyított teljesítményjavulásának és a tökéletes modell véletlen modellhez viszonyított teljesítményjavulásának aránya.
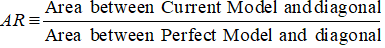
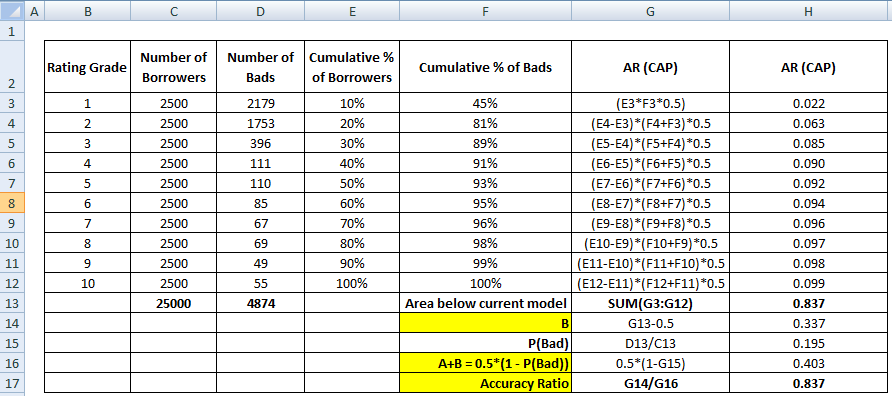
Először is ki kell számítani az aktuális modell és az átlós vonal közötti területet. Az aktuális modell alatti területet (beleértve az átlós vonal alatti területet is) a Trapézszabály numerikus integrációs módszerével tudjuk kiszámítani. A trapéz területe
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) az alintervallum szélessége és (yi + yi+1)*0,5 az átlagos magasság.
Ez esetben x a hitelfelvevők kumulatív arányának értékeire utal a különböző tizedes szinteken, y pedig a rossz ügyfelek kumulatív arányára utal a különböző tizedes szinteken. Az x0 és y0 értéke 0.
Mihelyt a fenti lépés megtörtént, a következő lépés a 0,5 levonása az előző lépésből visszaadott területből. Kíváncsi kell lennie a 0,5 relevanciájára. Ez az átlós vonal alatti terület. Azért vonjuk ki, mert csak az aktuális modell és az átlós vonal közötti területre van szükségünk (nevezzük B-nak).
Most szükségünk van a nevezőre, ami a tökéletes modell és az átlós vonal közötti terület, A + B. Ez egyenértékű a 0.5*(1 - Prob(Bad)) értékkel. Lásd az alábbi táblázatban látható összes számítási lépést –
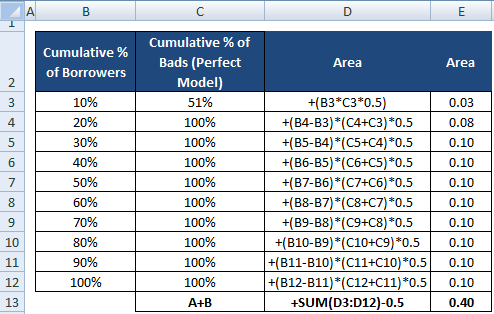
Az AR nevezője is kiszámítható úgy, ahogyan a számláló számítását elvégeztük. Ez azt jelenti, hogy a területet a “Hitelfelvevők kumulatív %-ának” és a “Rosszok kumulatív %-ának (Tökéletes modell)” felhasználásával számoljuk ki, majd ebből levonjuk a 0,5-öt, mivel az átlós vonal alatti területet nem kell figyelembe vennünk.
Az alábbi R-kódban példaként mintaadatokat készítettünk. A változó neve pred az előre jelzett valószínűségekre utal. A y változó a függő változóra (tényleges esemény) utal. Csak erre a két változóra van szükségünk a pontossági arány kiszámításához.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Gini együttható
A Gini együttható nagyon hasonló a CAP-hoz, de az összes ügyfél helyett a jó ügyfelek arányát (kumulatív) mutatja. Megmutatja, hogy a modell milyen mértékben rendelkezik jobb osztályozási képességekkel a véletlenszerű modellhez képest. Gini-indexnek is nevezik. A Gini-együttható -1 és 1 közötti értékeket vehet fel. A negatív értékek a pontszámok fordított jelentésű modellnek felelnek meg.
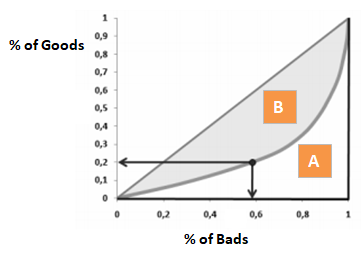
Gini = B / (A+B). Vagy Gini = 2B, mivel A + B területe 0,5
A Gini együttható számítási lépéseit lásd alább :
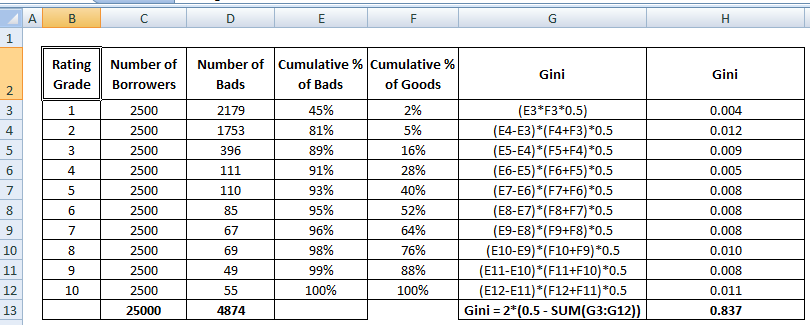
A jó ügyfelek x%-ának elutasításával együtt a rossz ügyfelek hány százalékát utasítjuk vissza.
A Gini együttható a Somer-féle D statisztika speciális esete. Ha rendelkezünk konkordancia és diszkordancia százalékkal, akkor kiszámíthatjuk a Gini-együtthatót.
Gini Coefficient = (Concordance percent - Discordance Percent)A konkordancia százalék azon párok arányára utal, ahol a hibázóknak nagyobb az előrejelzett valószínűsége, mint a jó ügyfeleké.
A diszkordancia százalék azon párok arányára utal, ahol a hibázóknak kisebb az előrejelzett valószínűsége, mint a jó ügyfeleké.
A Gini-együttható kiszámításának másik módja a konkordancia és a diszkordancia százalék felhasználása (a fenti magyarázat szerint). Lásd az alábbi R-kódot.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
A Gini-együttható és a pontossági arány egyenértékű?
Igen, mindig egyenlőek. Ezért a Gini-együtthatót néha pontossági aránynak (AR) is nevezik.
Igen, tudom, hogy a Gini és az AR tengelyei különböznek. Felmerül a kérdés, hogyan lehetnek még mindig ugyanazok. Ha megoldja az egyenletet, akkor azt találja, hogy a Gini együttható B területe megegyezik a B terület / Prob(Good) területével a pontossági arányban (ami egyenértékű (1/2)*AR ). Ha mindkét oldalt megszorozzuk 2-vel, akkor a Gini = 2*B és AR = B terület / (A + B terület)
A ROC-görbe alatti terület (AUC)
AUC vagy ROC-görbe mutatja a valódi pozitív eredmények arányát (a hibázó helyesen minősül hibázónak) a hamis pozitív eredmények arányával szemben (a nem hibázó tévesen minősül hibázónak).
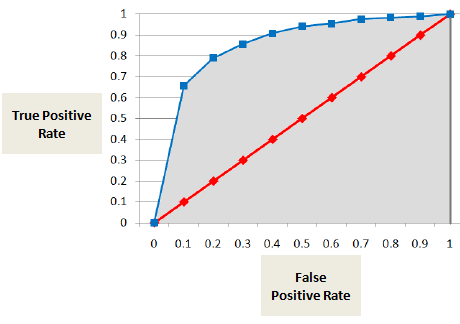
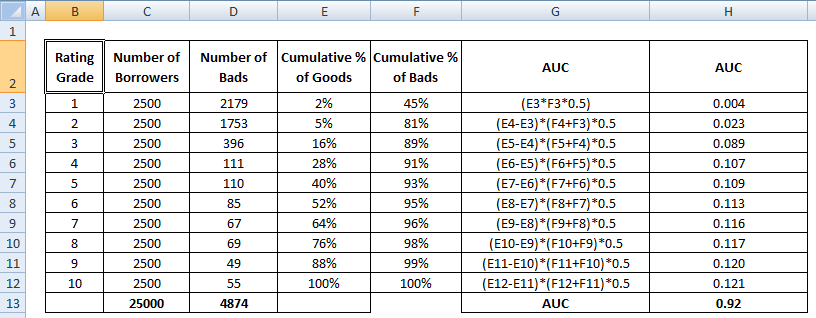
AUC-érték a minősítési fokozat vagy tized szintjén számított összes egyedi érték összegzése.
4 Az AUC kiszámításának módszerei Matematikailag
AUC és a Gini-együttható közötti kapcsolat
Gini = 2*AUC – 1.
Elgondolkodhat azon, hogy ezek hogyan kapcsolódnak egymáshoz.
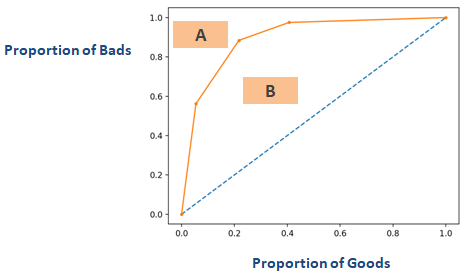
Ha megfordítjuk a fenti “Gini-együttható” nevű részben látható diagram tengelyét, akkor az alábbi diagramhoz hasonlót kapunk. Itt Gini = B / (A + B). A + B területe 0,5, tehát Gini = B / 0,5, ami egyszerűsítve Gini = 2*B. AUC = B + 0.5, ami tovább egyszerűsödik B = AUC – 0,5-re. Tegyük ezt az egyenletet Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1
.