Profilo di precisione cumulativa (CAP)
Il profilo di precisione cumulativa (CAP) di un modello di rating del credito mostra la percentuale di tutti i mutuatari (debitori) sull’asse x e la percentuale di inadempienti (cattivi clienti) sull’asse y. Nell’analitica di marketing, si chiamaGain Chart. È anche chiamata curva di potenza in alcuni altri domini.
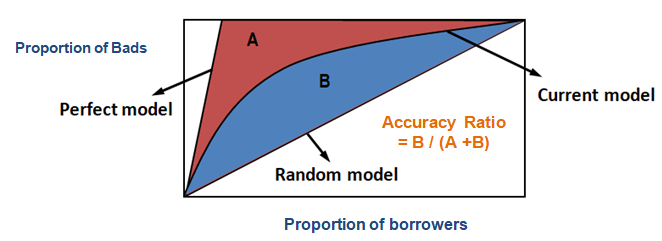
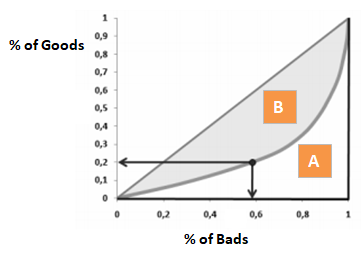
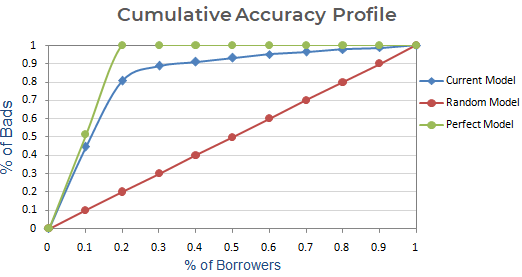
Utilizzando il CAP, puoi confrontare la curva del tuo modello attuale con la curva del modello ‘ideale o perfetto’ e puoi anche confrontarla con la curva del modello casuale. Il ‘modello perfetto’ si riferisce allo stato ideale in cui tutti i cattivi clienti (risultato desiderato) possono essere catturati direttamente. Il ‘modello casuale’ si riferisce allo stato in cui la proporzione di clienti cattivi è distribuita equamente. Il ‘Modello attuale’ si riferisce al tuo modello di probabilità di default (o qualsiasi altro modello su cui stai lavorando). Cerchiamo sempre di costruire il modello che si avvicina alla curva del modello perfetto. Possiamo leggere il modello attuale come “% di clienti cattivi coperti a un dato livello di decile”. Per esempio, l’89% dei clienti cattivi catturati selezionando solo il 30% dei debitori in base al modello.
- Ordina la probabilità di default stimata in ordine decrescente e dividila in 10 parti (decile). Significa che i mutuatari più rischiosi con alta PD dovrebbero essere al decile superiore e i mutuatari più sicuri dovrebbero apparire al decile inferiore. Dividere il punteggio in 10 parti non è una regola empirica. Invece si può usare il grado di rating.
- Calcolare il numero di mutuatari (osservazioni) in ogni decile
- Calcolare il numero di clienti cattivi in ogni decile
- Calcolare il numero cumulativo di clienti cattivi in ogni decile
- Calcolare la percentuale di clienti cattivi in ogni decile
- Calcolare la percentuale cumulativa di clienti cattivi in ogni decile
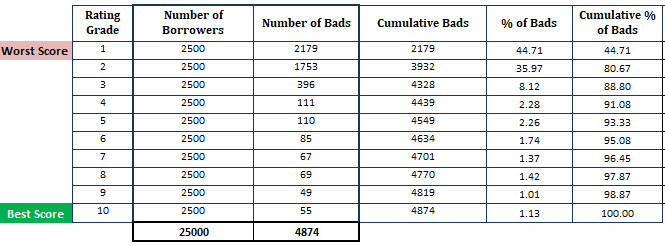
Fino ad ora, abbiamo fatto il calcolo in base al modello PD (ricordate che il primo passo è basato sulle probabilità ottenute dal modello PD).
Passo successivo: Quale dovrebbe essere il numero di clienti cattivi in ogni decile basato sul modello perfetto?
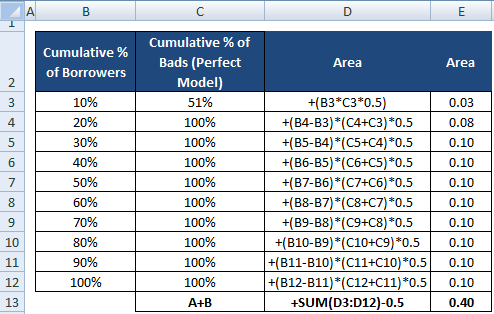
- Nel modello perfetto, il primo decile dovrebbe catturare tutti i clienti cattivi poiché il primo decile si riferisce al peggior grado di rating o ai mutuatari con la più alta probabilità di default. Nel nostro caso, il primo decile non può catturare tutti i clienti cattivi perché il numero di mutuatari che rientrano nel primo decile è inferiore al numero totale di clienti cattivi.
- Calcolare il numero cumulativo di clienti cattivi in ogni decile basato sul modello perfetto
- Calcolare la % cumulativa di clienti cattivi in ogni decile basato sul modello perfetto

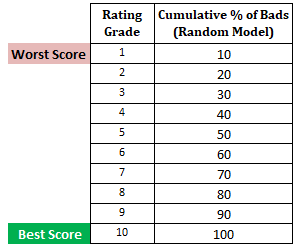
Passo successivo: Calcolare la percentuale cumulativa di clienti cattivi in ogni decile basato sul modello casuale Nel modello casuale, ogni decile dovrebbe costituire il 10%. Quando calcoliamo la % cumulativa, sarà il 10% nel decile 1, il 20% nel decile 2 e così via fino al 100% nel decile 10.
Passo successivo: Creare un grafico con la % cumulativa di cattivi basata sul modello corrente, casuale e perfetto. Nell’asse x, mostra la percentuale di mutuatari (osservazioni) e l’asse y rappresenta la percentuale di Bad Customers.
Accuracy Ratio
Nel caso del CAP (Cumulative Accuracy Profile), Accuracy ratio è il rapporto tra l’area tra il tuo attuale modello predittivo e la linea diagonale e l’area tra il modello perfetto e la linea diagonale. In altre parole, è il rapporto tra il miglioramento delle prestazioni del modello attuale rispetto al modello casuale e il miglioramento delle prestazioni del modello perfetto rispetto al modello casuale.
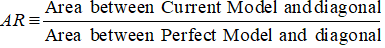
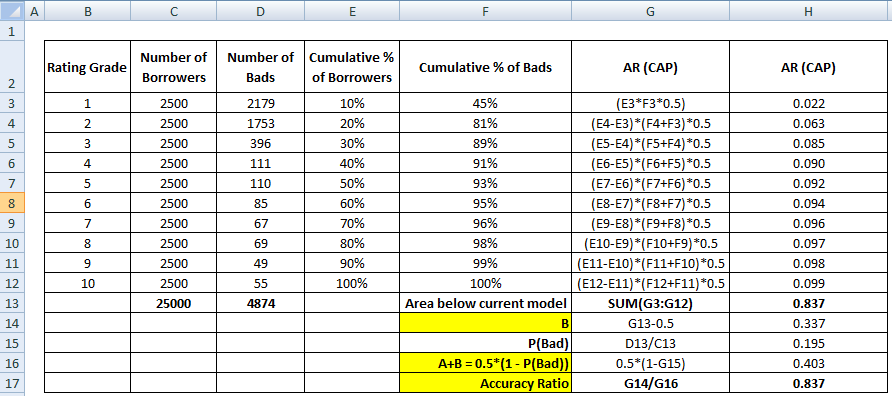
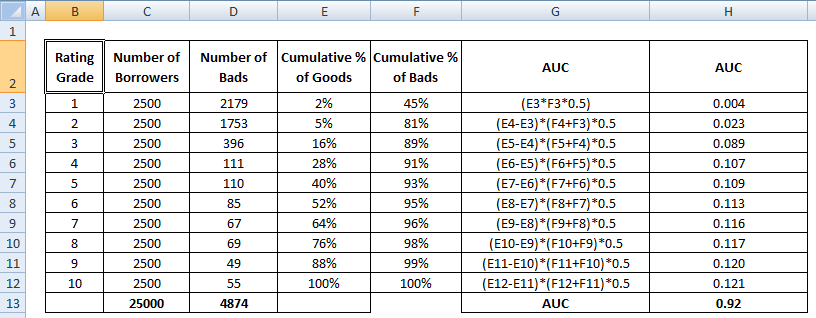
Il primo passo è calcolare l’area tra il modello attuale e la linea diagonale. Possiamo calcolare l’area sotto il modello corrente (inclusa l’area sotto la linea diagonale) usando il metodo di integrazione numerica della regola trapezoidale. L’area di un trapezio è
( xi+1 – xi ) * ( yi + yi+1 ) * 0.5

( xi+1 – xi ) è la larghezza del sottointervallo e (yi + yi+1)*0.5 è l’altezza media. Il valore di x0 e y0 è 0.
Una volta completato il passo precedente, il passo successivo è quello di sottrarre 0,5 dall’area restituita dal passo precedente. Vi starete chiedendo l’importanza di 0,5. È l’area sotto la linea diagonale. Stiamo sottraendo perché abbiamo bisogno solo dell’area tra il modello attuale e la linea diagonale (chiamiamola
B).Ora abbiamo bisogno del denominatore che è l’area tra il modello perfetto e la linea diagonale,
A + B. È equivalente a0.5*(1 - Prob(Bad)). Vedere tutti i passi di calcolo mostrati nella tabella qui sotto –Il denominatore di AR può anche essere calcolato come abbiamo fatto per il numeratore. Significa calcolare l’area usando “Cumulative % of Borrowers” e “Cumulative % of Bads (Perfect Model)” e poi sottrarre 0.5 da esso poiché non abbiamo bisogno di considerare l’area sotto la linea diagonale.
Il metodo precedente di calcolo del rapporto di accuratezza (AR) è approssimativo poiché abbiamo considerato i dati in 10 bins (valutazioni) e ricordate che il numero di bins non è uguale al numero di punti dati. Non c’è bisogno di grattarsi la testa – I passi del calcolo sono gli stessi. E’ solo che abbiamo bisogno di applicarli in valori grezzi invece che in valutazioni (in bins / decile) per ottenere l’AR esatta. Fare riferimento sotto per la stima esatta.Nel codice R qui sotto, abbiamo preparato i dati di esempio. Il nome della variabile
predsi riferisce alle probabilità previste. La variabileysi riferisce alla variabile dipendente (evento effettivo). Abbiamo bisogno solo di queste due variabili per calcolare l’Accuracy Ratio.library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)Coefficiente di Gini
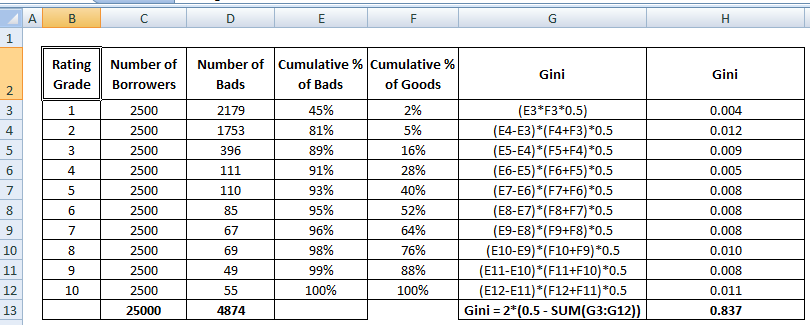
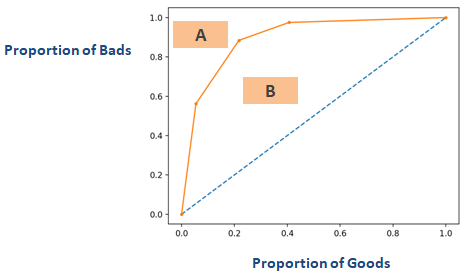
Il coefficiente di Gini è molto simile al CAP ma mostra la proporzione (cumulativa) di buoni clienti invece di tutti i clienti. Mostra la misura in cui il modello ha migliori capacità di classificazione rispetto al modello casuale. È anche chiamato indice di Gini. Il coefficiente di Gini può assumere valori compresi tra -1 e 1. Valori negativi corrispondono a un modello con significati invertiti dei punteggi.
Gini = B / (A+B). Oppure Gini = 2B poiché l’area di A + B è 0,5
Vedi i passi di calcolo del coefficiente di Gini qui sotto :
InterpretazioneRifiutando l’x% di clienti buoni, quale percentuale di clienti cattivi rifiutiamo insieme.
Il coefficiente di Gini è un caso speciale della statistica D di Somer. Se hai la percentuale di concordanza e discordanza, puoi calcolare il coefficiente di Gini.
Gini Coefficient = (Concordance percent - Discordance Percent)La percentuale di concordanza si riferisce alla proporzione di coppie in cui gli inadempienti hanno una probabilità prevista più alta dei buoni clienti.
La percentuale di discordanza si riferisce alla proporzione di coppie in cui gli inadempienti hanno una probabilità prevista più bassa dei buoni clienti.Un altro modo di calcolare il coefficiente di Gini è usare la percentuale di concordanza e discordanza (come spiegato sopra). Vedere il codice R qui sotto.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)Il coefficiente di Gini e il rapporto di precisione sono equivalenti?
Sì, sono sempre uguali. Quindi il Coefficiente di Gini è a volte chiamato Accuracy Ratio (AR).
Sì, so che gli assi in Gini e AR sono diversi. Si pone la domanda su come siano ancora uguali. Se risolvete l’equazione, troverete che l’Area B nel Coefficiente di Gini è uguale all’Area B / Prob(Good) nel Rapporto di Precisione (che è equivalente a (1/2)*AR). Moltiplicando entrambi i lati per 2, si otterrà Gini = 2*B e AR = Area B / (Area A + B)
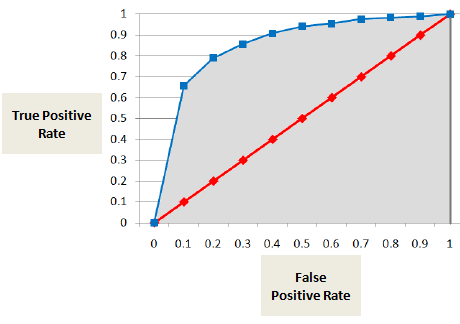
Area sotto la curva ROC (AUC)
AUC o curva ROC mostra la proporzione di veri positivi (l’inadempiente è classificato correttamente come inadempiente) rispetto alla proporzione di falsi positivi (il non inadempiente è classificato erroneamente come inadempiente).
Il punteggio AUC è la somma di tutti i valori individuali calcolati a livello di rating grade o decile.
4 Metodi per calcolare l’AUC MatematicamenteRelazione tra AUC e coefficiente Gini
Gini = 2*AUC – 1.
Ti starai chiedendo come sono correlati.
Se inverti l’asse del grafico mostrato nella sezione precedente chiamata “Coefficiente di Gini”, otterrai simile al grafico qui sotto. Qui
Gini = B / (A + B). L’area di A + B è 0,5 quindi Gini = B / 0,5 che si semplifica inGini = 2*B.AUC = B + 0.5che si semplifica ulteriormente a B = AUC – 0,5. Metti questa equazione inGini = 2*B
Gini = 2*(AUC – 0.5)
Gini = 2*AUC – 1