Cumulative Accuracy Profile (CAP)
信用格付けモデルの累積精度プロファイル(CAP)は、X軸にすべての借り手(債務者)の割合、Y軸にデフォルト者(不良顧客)の割合が示されています。 マーケティング分析ではGain Chartと呼ばれる。 また、他の分野ではPower Curveとも呼ばれています。
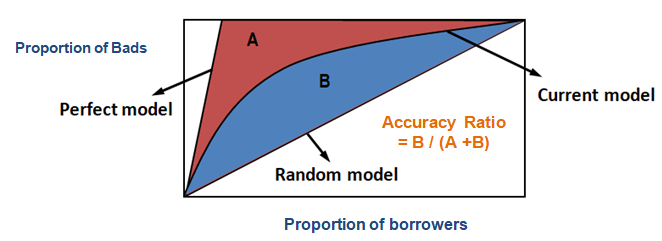
CAPを使って、現在のモデルの曲線と「理想または完全」モデルの曲線を比較でき、ランダムモデルの曲線と比較することも可能です。 完璧なモデル」とは、すべての不良顧客(望ましい結果)を直接捕らえることができる理想的な状態を指します。 ランダム・モデル」とは、不良顧客の割合が均等に分布している状態を指します。 現在のモデル」は、デフォルトの確率モデル(または、あなたが取り組んでいる他のモデル)を指します。 私たちは常に、完全モデルの曲線に傾く(近づく)ようなモデルを構築しようとします。 現在のモデルは、「与えられたデシルレベルでカバーされる不良顧客の割合」として読むことができます。 例えば、モデルに基づいて債務者の上位30%を選択するだけで、不良顧客の89%が捕捉されます。
- 推定デフォルト確率を降順に並べ替えて、10分割(10マイル)する。 つまり、PDの高い最もリスクの高い借り手は上位のdecileに、最も安全な借り手は下位のdecileに表示されるはずである。 10分割は経験則ではない。 その代わり、格付けのグレードを使うことができる。
- 各デシルにおける借り手(オブザベーション)の数を計算する
- 各デシルにおける不良顧客の数を計算する
- 各デシルにおける不良顧客の累積数を計算する各デカイルにおける不良顧客の割合を算出する
- 各デカイルにおける不良顧客の累積割合を算出する
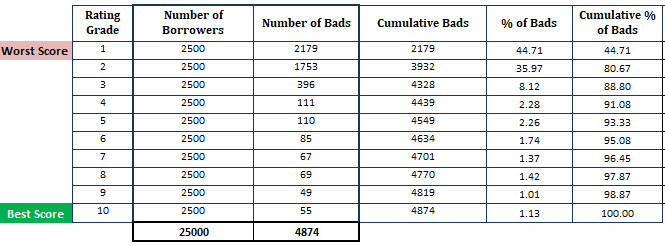
今までは。 PDモデルに基づいて計算を行いました(最初のステップはPDモデルから得られた確率に基づいていることを思い出してください)。
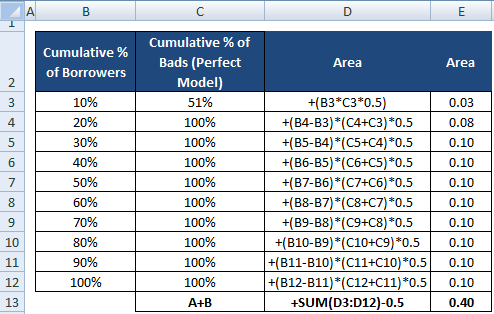
Next step : 完璧なモデルに基づいて、各十分位における不良顧客の数はどうあるべきか?
- 完璧なモデルでは、第一十分位は最悪の格付け等級またはデフォルトする可能性が最も高い借り手を指すので、すべての不良顧客を捕捉しなければならないはずです。 この場合、第一十分位は不良顧客の総数より少ないので、すべての不良顧客を捕捉することはできません。
- 完全モデルに基づいて各十分位における不良顧客の累積数を計算する
- 完全モデルに基づいて各十分位における不良顧客の累積%を計算する

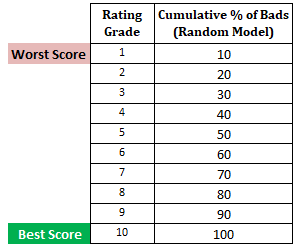
次のステップ:ランダムモデルに基づいて各十分位における不良顧客の累積%を計算ランダムモデルでは、各十分位の構成率は10%とする必要があります。
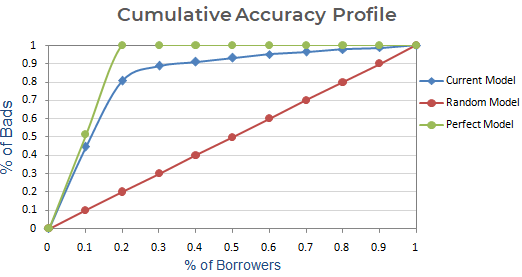
Next step : Current, Random and Perfect Modelに基づくCumulative % of Badsでグラフを作成します。 x軸は、借り手(オブザベーション)のパーセンテージを示し、y軸は不良顧客のパーセンテージを示します。
精度比
CAP(累積精度プロファイル)の場合、精度比とは、現在の予測モデルと対角線の間の領域と完全モデルと対角線の間の領域の比を指します。 言い換えれば、ランダムなモデルに対する現在のモデルのパフォーマンス向上と、ランダムなモデルに対する完全なモデルのパフォーマンス向上の比率です。
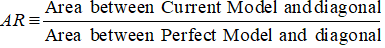
最初のステップは、現在のモデルと対角線の間の領域を計算することです。 台形則数値積分法を用いて、現在のモデルより下の面積(対角線より下の面積も含む)を計算することができます。 台形の面積は
( xi+1 – xi ) * ( yi + yi+1 ) * 0.5

( xi+1 – xi ) は部分区間の幅で、 (yi + yi+1)*0.5 は平均高です。
この場合、xは異なる10マイルレベルでの借り手の累積割合の値を、yは異なる10マイルレベルの不良顧客の累積割合の値を意味しています。 x0とy0の値は0です。
上記のステップが完了すると、次のステップは前のステップで返された面積から0.5を差し引くことです。 0.5という数字が気になりますよね。 これは、対角線より下の面積です。 引き算をするのは、現在のモデルと対角線の間の面積(仮にBとします)だけが必要だからです。
次に、完全モデルと対角線の間の面積である分母A + Bを求めます。 これは0.5*(1 - Prob(Bad))と等価である。
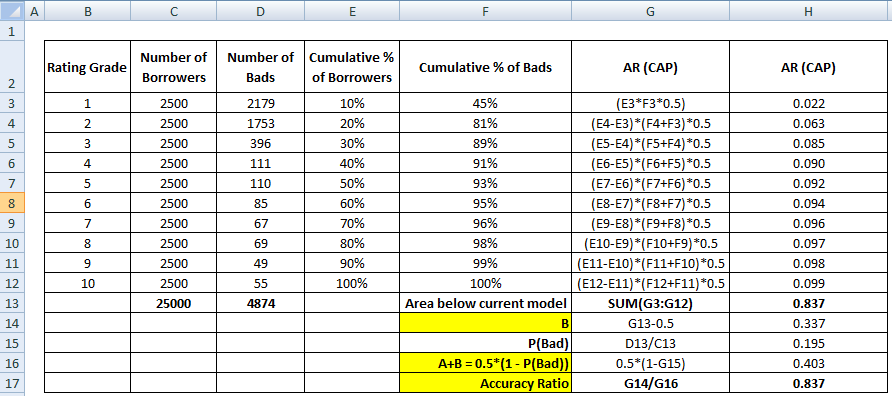
ARの分母も分子の計算と同様に計算することができる。
以下のRコードでは、例としてサンプルデータを用意しています。 変数名predは予測確率を表しています。 変数名yは従属変数(実際の出来事)です。
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Gini Coefficient
Gini CoefficientはCAPに非常に似ていますが、これは全顧客ではなく、良い顧客の割合(累積)を示しています。 これは、モデルがランダム・モデルと比較して、より良い分類能力を持つ程度を示しています。 これはジニ指数とも呼ばれます。 ジニ係数は-1から1の間の値を取ることができます。負の値は、スコアの逆の意味を持つモデルに対応します。
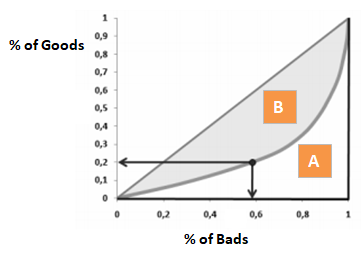
Gini = B / (A+B). または、A+Bの面積が0.5なので、ジニ=2B
ジニ係数の計算手順を以下に示します。
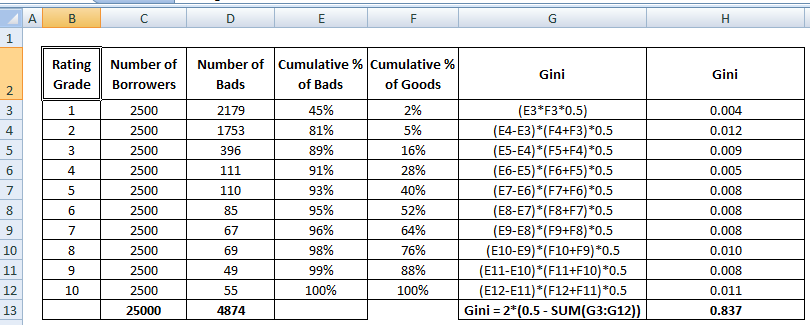
良い顧客のx%を拒否することによって、悪い顧客の何%も一緒に拒否する。
ジニ係数はソマーのD統計の特殊ケースです。 一致率と不一致率があれば、ジニ係数を計算することができる。
Gini Coefficient = (Concordance percent - Discordance Percent)Concordance percentとは、不良顧客が優良顧客よりも高い予測確率を持つ組の割合のことで、
Discordance percentとは、不良顧客が優良顧客よりも低い予測確率を持つ組の割合のこと。
Gini Coefficientのもう一つの計算方法には、(上記のように)コンコーダンスとディスコーダンスパーセントを使っています。
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
ジニ係数と精度比は等価か?
はい、常に等価です。
はい、ジニ係数と精度比の軸が異なることは知っています。 しかし、どうして同じなのでしょうか。 この式を解くと、ジニ係数のB面積は、精度比のB面積/Prob(Good)と同じになります((1/2)*ARと等価です)。 両辺に2を掛けると、ジニ=2*B、AR=面積B÷(面積A+B)
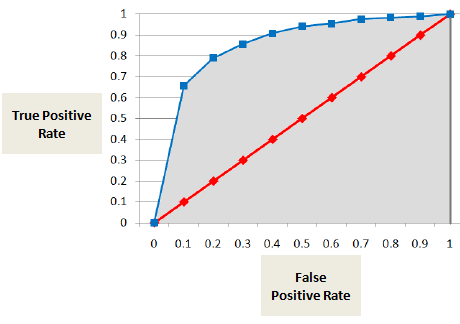
Area under ROC Curve (AUC)
AUC または ROC曲線は、真陽性(不良債権者が不良債権者として正しく分類される)の割合と偽陽性(不良債権者が不良債権者として間違って分類される)割合の差を示す。
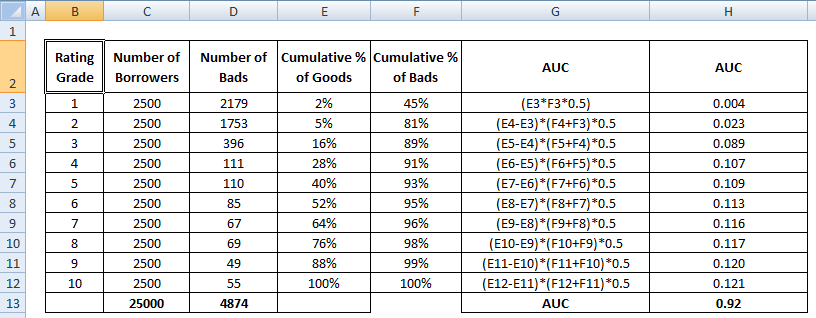
AUC score is the sumation of all the individual values calculated at rating grade or decile level.
4 Methods to calculate AUC Mathematically
Relationship between AUC and Gini Coefficient
Gini = 2*AUC – 1.AUC = 1.AUC – 1.
両者の関係が気になるところですが、
上の「ジニ係数」で示したグラフの軸を逆にすると、下のようなグラフが得られます。 ここでGini = B / (A + B)。 A+Bの面積は0.5ですから、ジニ=B÷0.5となり、単純化してGini = 2*Bとなります。 AUC = B + 0.5となり、さらにB = AUC – 0.5と単純化される。 この式をGini = 2*B
Gini = 2*(AUC – 0.5)
Gini = 2*AUC – 1
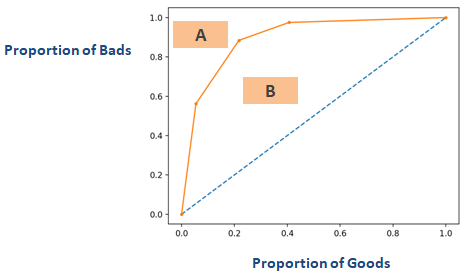
で置くと、次のようになります。