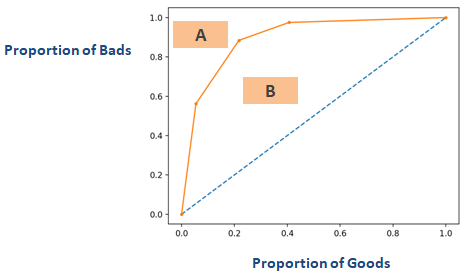
Cumulatief Nauwkeurigheidsprofiel (CAP)
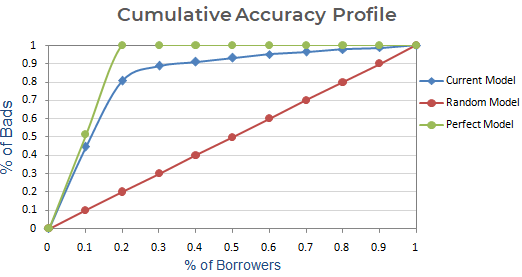
Cumulatief Nauwkeurigheidsprofiel (CAP) van een kredietbeoordelingsmodel toont het percentage van alle leners (debiteuren) op de x-as en het percentage wanbetalers (slechte klanten) op de y-as. In marketinganalyses wordt hetGain Chartgenoemd. In sommige andere domeinen wordt hij ook Power Curve genoemd.
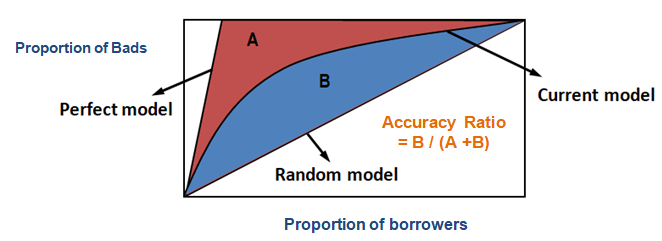
Met behulp van CAP kunt u de curve van uw huidige model vergelijken met de curve van een ‘ideaal of perfect’ model en kunt u hem ook vergelijken met de curve van een willekeurig model. Het “perfecte model” verwijst naar de ideale toestand waarin alle slechte klanten (gewenste uitkomst) direct kunnen worden opgevangen. Het “willekeurige model” verwijst naar de toestand waarin het aandeel slechte klanten gelijk verdeeld is. Het “huidige model” verwijst naar uw kans op wanbetaling model (of een ander model waar u aan werkt). We proberen altijd een model te bouwen dat dichter bij de curve van het perfecte model ligt. We kunnen het huidige model lezen als “% slechte klanten gedekt op een bepaald decielniveau”. Bijvoorbeeld, 89% van de slechte klanten wordt gedekt door op basis van het model alleen de top 30% van de debiteuren te selecteren.
- Sorteer de geraamde kans op wanbetaling in aflopende volgorde en splits deze op in 10 delen (deciel). Dit betekent dat de riskantste kredietnemers met een hoge PD in het bovenste deciel moeten staan en de veiligste in het onderste deciel. Het splitsen van de score in 10 delen is geen vuistregel. In plaats daarvan kunt u rating rang gebruiken.
- Bereken aantal leners (waarnemingen) in elk deciel
- Bereken aantal slechte klanten in elk deciel
- Bereken cumulatief aantal slechte klanten in elk deciel
- Bereken percentage slechte klanten in elk deciel
- Bereken cumulatief percentage slechte klanten in elk deciel
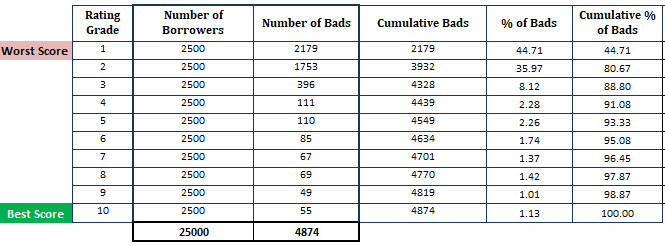
Tot nu toe, hebben we berekeningen gemaakt op basis van het PD-model (onthoud dat de eerste stap is gebaseerd op de waarschijnlijkheden die uit het PD-model zijn verkregen).
Volgende stap: Wat moet het aantal slechte klanten in elk deciel zijn op basis van het perfecte model?
- In het perfecte model moet het eerste deciel alle slechte klanten omvatten, aangezien het eerste deciel verwijst naar de slechtste ratingcategorie OF de kredietnemers met de hoogste kans op wanbetaling. In ons geval, kan eerste deciel niet alle slechte klanten vangen aangezien het aantal leners die in het eerste deciel vallen minder dan het totale aantal slechte klanten is.
- Bereken cumulatief aantal slechte klanten in elk deciel op basis van perfect model
- Bereken cumulatief % slechte klanten in elk deciel op basis van perfect model

Volgende stap: Bereken het cumulatieve percentage slechte klanten in elk deciel op basis van willekeurig modelIn het willekeurige model moet elk deciel 10% uitmaken. Wanneer we het cumulatieve % berekenen, is dit 10% in deciel 1, 20% in deciel 2 enzovoort tot 100% in deciel 10.
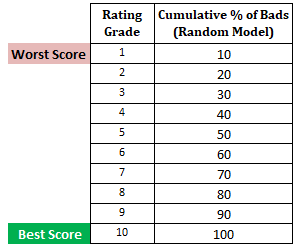
Volgende stap: Maak een grafiek met het cumulatieve % slechte klanten op basis van het huidige, willekeurige en perfecte model. Op de x-as staat het percentage leners (waarnemingen) en op de y-as het percentage slechte klanten.
Nauwkeurigheidsverhouding
In het geval van CAP (Cumulatief Nauwkeurigheidsprofiel) is de Nauwkeurigheidsverhouding de verhouding tussen het gebied tussen uw huidige voorspellende model en de diagonale lijn en het gebied tussen het perfecte model en de diagonale lijn. Met andere woorden, het is de verhouding tussen de prestatieverbetering van het huidige model ten opzichte van het willekeurige model en de prestatieverbetering van het perfecte model ten opzichte van het willekeurige model.
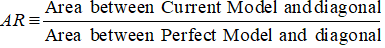
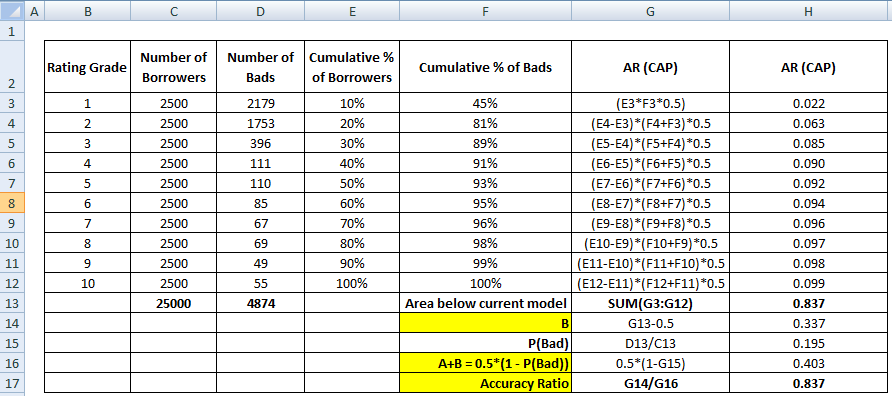
Eerste stap is het berekenen van het gebied tussen het huidige model en de diagonale lijn. We kunnen het gebied onder het huidige model (inclusief het gebied onder de diagonale lijn) berekenen met behulp van de Numerieke Integratiemethode van de Trapeziumregel. De oppervlakte van een trapezium is
( xi+1 – xi ) * ( yi + yi+1 ) * 0.5

( xi+1 – xi ) is de breedte van het subinterval en (yi + yi+1)*0.5 is de gemiddelde hoogte.
In dit geval verwijst x naar de waarden van het cumulatieve aandeel kredietnemers in de verschillende decielen en y verwijst naar het cumulatieve aandeel slechte klanten in de verschillende decielen. De waarde van x0 en y0 is 0.
Als bovenstaande stap is voltooid, is de volgende stap 0,5 af te trekken van het gebied dat uit de vorige stap is verkregen. Je vraagt je vast af wat 0.5 betekent. Het is het gebied onder de diagonale lijn. We trekken af omdat we alleen de oppervlakte tussen het huidige model en de diagonale lijn nodig hebben (laten we het B noemen).
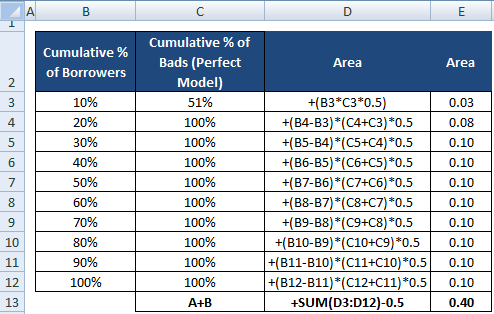
Nu hebben we de noemer nodig, dat is de oppervlakte tussen het perfecte model en de diagonale lijn, A + B. Het is gelijk aan 0.5*(1 - Prob(Bad)). Zie alle berekeningsstappen in de tabel hieronder –
De noemer van AR kan ook worden berekend zoals we de berekening voor de teller hebben uitgevoerd. Dit betekent dat het gebied wordt berekend met behulp van “Cumulatief % leners” en “Cumulatief % slechte leners (perfect model)” en vervolgens 0,5 ervan wordt afgetrokken, aangezien we het gebied onder de diagonale lijn niet hoeven te beschouwen.
In de R-code hieronder, we voorbereid steekproefgegevens voor voorbeeld. Variabele naam pred verwijst naar voorspelde kansen. Variabele y verwijst naar afhankelijke variabele (werkelijke gebeurtenis). We hebben alleen deze twee variabelen nodig om de nauwkeurigheidsratio te berekenen.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Gini-coëfficiënt
Gini-coëfficiënt lijkt sterk op CAP, maar toont de proportie (cumulatief) van goede klanten in plaats van alle klanten. Het geeft aan in welke mate het model betere classificatiemogelijkheden heeft in vergelijking met het willekeurige model. Hij wordt ook Gini Index genoemd. De Gini-coëfficiënt kan waarden aannemen tussen -1 en 1. Negatieve waarden komen overeen met een model met omgekeerde betekenissen van scores.
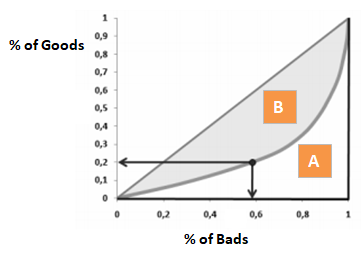
Gini = B / (A+B). Of Gini = 2B aangezien Oppervlakte van A + B 0,5 is
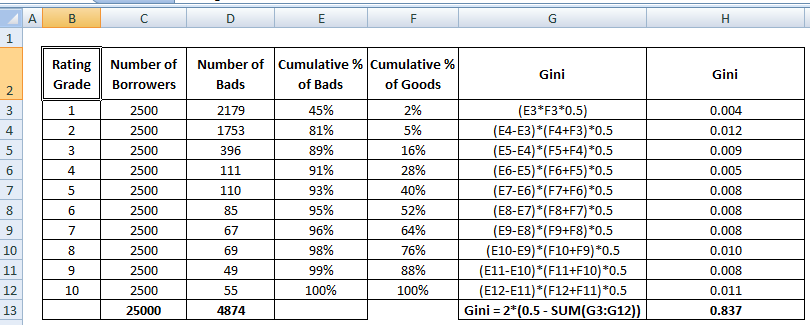
Zie de berekeningsstappen van Gini-coëfficiënt hieronder :
Door x% van de goede klanten af te wijzen, welk percentage slechte klanten wijzen we hiernaast af.
Gini-coëfficiënt is een speciaal geval van Somer’s D-statistiek. Als je concordantie- en discordantiepercentages hebt, kun je de Gini-coëfficiënt berekenen.
Gini Coefficient = (Concordance percent - Discordance Percent)Concordantiepercentage verwijst naar het percentage paren waarbij wanbetalers een hogere voorspelde waarschijnlijkheid hebben dan de goede klanten.
Discordantiepercentage verwijst naar het percentage paren waarbij wanbetalers een lagere voorspelde waarschijnlijkheid hebben dan de goede klanten.
Een andere manier om de Gini-coëfficiënt te berekenen, is met behulp van concordantie- en discordantiepercentages (zoals hierboven uitgelegd). Zie de R-code hieronder.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Zijn Gini-coëfficiënt en Nauwkeurigheidsverhouding gelijkwaardig?
Ja, ze zijn altijd gelijk. Daarom wordt de Gini-coëfficiënt ook wel de Nauwkeurigheidsverhouding (AR) genoemd.
Ja, ik weet dat de assen in Gini en AR verschillend zijn. De vraag rijst hoe ze nog steeds gelijk zijn. Als je de vergelijking oplost, zou je vinden dat Oppervlakte B in de Gini-coëfficiënt hetzelfde is als Oppervlakte B / Prob(Good) in de Nauwkeurigheidsratio (wat gelijk is aan (1/2)*AR ). Als u beide zijden met 2 vermenigvuldigt, krijgt u Gini = 2*B en AR = Gebied B / (Gebied A + B)
Area under ROC Curve (AUC)
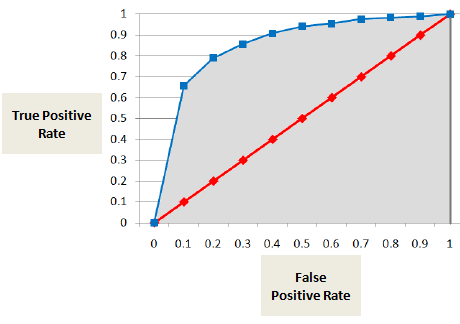
AUC of ROC-curve toont het percentage echte positieven (wanbetaler wordt correct als wanbetaler geclassificeerd) tegenover het percentage valse positieven (niet-de wanbetaler wordt ten onrechte als wanbetaler geclassificeerd).
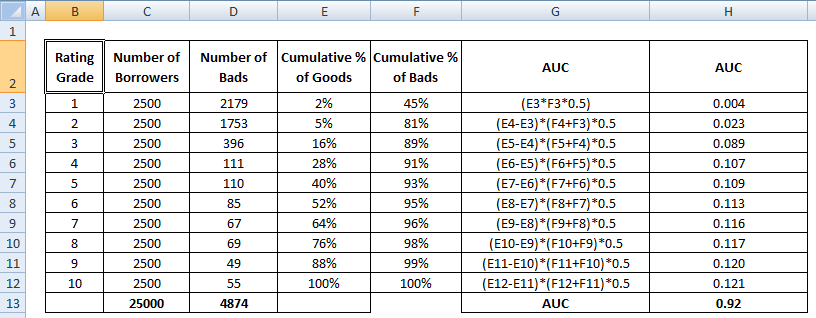
De AUC-score is de som van alle individuele waarden die op rating- of decilevelniveau zijn berekend.
4 Methoden om AUC wiskundig te berekenen
Relatie tussen AUC en Gini-coëfficiënt
Gini = 2*AUC – 1.
U vraagt zich vast af hoe ze met elkaar in verband staan.
Als u de as van de grafiek in het bovenstaande gedeelte met de naam “Gini-coëfficiënt” omdraait, krijgt u ongeveer dezelfde grafiek als hieronder. Hier Gini = B / (A + B). Oppervlakte van A + B is 0,5 dus Gini = B / 0,5 wat vereenvoudigt tot Gini = 2*B. AUC = B + 0.5, wat verder vereenvoudigt tot B = AUC – 0,5. Zet deze vergelijking in Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1