Cumulative Accuracy Profile (CAP)
Cumulative Accuracy Profile (CAP) of a credit rating model shows percentage of all borrowers (debtors) on the x-axis and the percentage of defaulters (bad customers) on the y-axis. W analityce marketingowej nazywana jestGain Chart. Jest również nazywana krzywą mocy w niektórych innych dziedzinach.
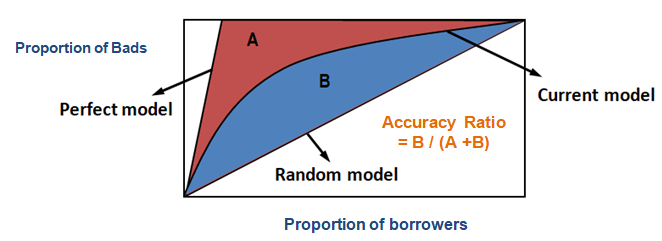
Używając CAP, można porównać krzywą bieżącego modelu z krzywą 'idealnego lub doskonałego’ modelu, a także porównać ją z krzywą modelu losowego. 'Idealny model’ odnosi się do idealnego stanu, w którym wszyscy źli klienci (pożądany wynik) mogą być uchwyceni bezpośrednio. Model losowy’ odnosi się do stanu, w którym proporcje złych klientów są równo rozłożone. Model bieżący” odnosi się do modelu prawdopodobieństwa niewypłacalności (lub jakiegokolwiek innego modelu, nad którym pracujesz). Zawsze staramy się zbudować model, który zbliża się do krzywej modelu idealnego. Możemy odczytać bieżący model jako „% złych klientów objętych danym poziomem decylowym”. Na przykład, 89% złych klientów zostało ujętych poprzez wybranie 30% najlepszych dłużników na podstawie modelu.
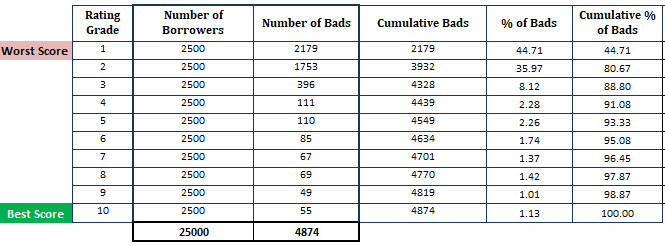
- Sortuj szacowane prawdopodobieństwo niewypłacalności w porządku malejącym i podziel je na 10 części (decyli). Oznacza to, że najbardziej ryzykowni kredytobiorcy z wysokim PD powinni znaleźć się w górnym decylu, a najbezpieczniejsi w dolnym. Podział oceny na 10 części nie jest regułą. Zamiast tego można użyć rating grade.
- Obliczyć liczbę kredytobiorców (obserwacji) w każdym decylu
- Obliczyć liczbę złych klientów w każdym decylu
- Obliczyć skumulowaną liczbę złych klientów w każdym decylu
- Obliczyć procent złych klientów w każdym decylu
- Obliczyć skumulowany procent złych klientów w każdym decylu
.
Do tej pory, wykonaliśmy obliczenia na podstawie modelu PD (pamiętaj, że pierwszy krok jest oparty na prawdopodobieństwach uzyskanych z modelu PD).
Kolejny krok: Jaka powinna być liczba złych klientów w każdym decylu w oparciu o model idealny?
- W modelu idealnym, pierwszy decyl powinien obejmować wszystkich złych klientów, ponieważ pierwszy decyl odnosi się do najgorszej klasy ratingowej LUB kredytobiorców z najwyższym prawdopodobieństwem niewypłacalności. W naszym przypadku pierwszy decyl nie może uchwycić wszystkich złych klientów, ponieważ liczba kredytobiorców mieszczących się w pierwszym decylu jest mniejsza niż całkowita liczba złych klientów.
- Obliczyć skumulowaną liczbę złych klientów w każdym decylu w oparciu o model idealny
- Obliczyć skumulowany % złych klientów w każdym decylu w oparciu o model idealny

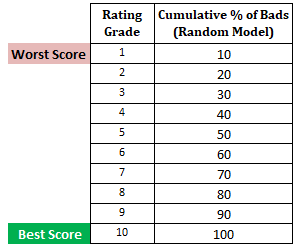
Krok następny : Obliczyć skumulowany % złych klientów w każdym decylu w oparciu o model losowyW modelu losowym każdy decyl powinien stanowić 10%. Kiedy obliczymy skumulowany %, będzie to 10% w decylu 1, 20% w decylu 2 i tak dalej aż do 100% w decylu 10.
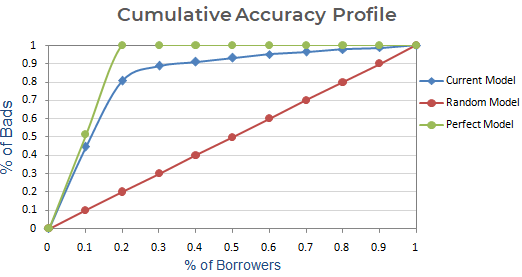
Krok następny : Utwórz wykres ze skumulowanym % złych klientów w oparciu o bieżący, losowy i doskonały model. Na osi x, pokazuje procent kredytobiorców (obserwacje), a oś y reprezentuje procent Złych Klientów.
Stosunek dokładności
W przypadku CAP (Skumulowany Profil Dokładności), Stosunek dokładności jest stosunkiem obszaru pomiędzy twoim bieżącym modelem predykcyjnym i linią ukośną oraz obszarem pomiędzy idealnym modelem i linią ukośną. Innymi słowy, jest to stosunek poprawy wydajności bieżącego modelu nad modelem losowym do poprawy wydajności modelu idealnego nad modelem losowym.
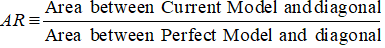
Pierwszym krokiem jest obliczenie obszaru pomiędzy bieżącym modelem a linią ukośną. Możemy obliczyć obszar pod bieżącym modelem (w tym obszar pod linią ukośną) używając metody całkowania numerycznego z regułą trapezową. Obszar trapezu to
( xi+1 – xi ) * ( yi + yi+1 ) * 0.5

( xi+1 – xi ) to szerokość podprzedziału, a (yi + yi+1)*0.5 to średnia wysokość.
W tym przypadku x odnosi się do wartości skumulowanego odsetka kredytobiorców na różnych poziomach decylowych, a y odnosi się do skumulowanego odsetka złych klientów na różnych poziomach decylowych. Wartość x0 i y0 wynosi 0.
Po wykonaniu powyższego kroku, kolejnym krokiem jest odjęcie 0.5 od obszaru zwróconego w poprzednim kroku. Pewnie zastanawiasz się nad znaczeniem 0.5. Jest to obszar poniżej linii ukośnej. Odejmujemy, ponieważ potrzebujemy tylko obszar pomiędzy obecnym modelem a linią ukośną (nazwijmy go B).
Teraz potrzebujemy mianownika, który jest obszarem pomiędzy idealnym modelem a linią ukośną, A + B. Jest on równoważny 0.5*(1 - Prob(Bad)). Zobacz wszystkie kroki obliczeniowe pokazane w poniższej tabeli –
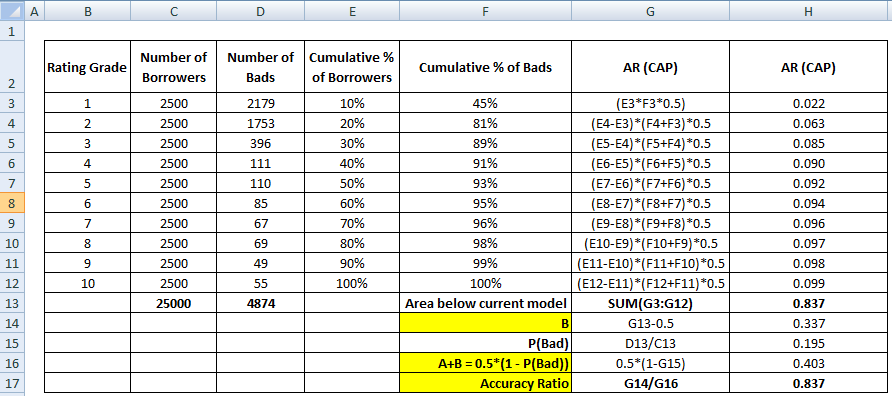
Denominator AR może być również obliczony tak, jak wykonaliśmy obliczenia dla licznika. Oznacza to obliczenie obszaru przy użyciu „Skumulowanego % pożyczkobiorców” i „Skumulowanego % złych (model idealny)”, a następnie odjęcie od niego 0,5, ponieważ nie musimy brać pod uwagę obszaru poniżej linii ukośnej.
W kodzie R poniżej, przygotowaliśmy przykładowe dane dla przykładu. Nazwa zmiennej pred odnosi się do przewidywanych prawdopodobieństw. Zmienna y odnosi się do zmiennej zależnej (rzeczywiste zdarzenie). Potrzebujemy tylko tych dwóch zmiennych do obliczenia Accuracy Ratio.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
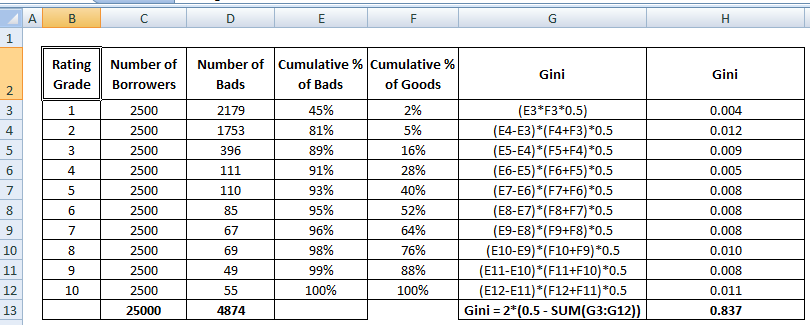
Współczynnik Giniego
Współczynnik Giniego jest bardzo podobny do CAP, ale pokazuje proporcję (kumulatywną) dobrych klientów zamiast wszystkich klientów. Pokazuje stopień, w jakim model ma lepsze możliwości klasyfikacji w porównaniu z modelem losowym. Jest on również nazywany wskaźnikiem Giniego. Współczynnik Giniego może przyjmować wartości od -1 do 1. Wartości ujemne odpowiadają modelowi o odwróconym znaczeniu punktacji.
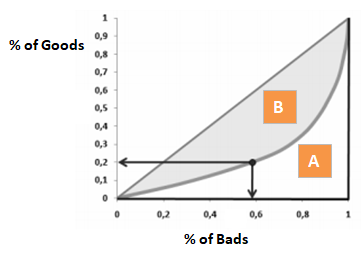
Gini = B / (A+B). Lub Gini = 2B ponieważ pole powierzchni A + B wynosi 0,5
Zobacz kroki obliczania współczynnika Giniego poniżej :
Odrzucając x% dobrych klientów, jaki procent złych klientów odrzucamy obok.
Współczynnik Giniego jest specjalnym przypadkiem statystyki Somer’s D. Jeśli mamy procent zgodności i niezgodności, możemy obliczyć współczynnik Giniego.
Gini Coefficient = (Concordance percent - Discordance Percent)Concordance percent odnosi się do proporcji par, w których defaulters mają wyższe przewidywane prawdopodobieństwo niż dobrzy klienci.
Discordance percent odnosi się do proporcji par, w których defaulters mają niższe przewidywane prawdopodobieństwo niż dobrzy klienci.
Innym sposobem obliczenia współczynnika Giniego jest użycie concordance i discordance percent (jak wyjaśniono powyżej). Odwołaj się do kodu R poniżej.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Czy Współczynnik Giniego i Współczynnik Dokładności są równoważne?
Tak, zawsze są równe. Stąd Współczynnik Giniego jest czasami nazywany Współczynnikiem Dokładności (AR).
Tak, wiem, że osie w Gini i AR są różne. Pytanie rodzi się, jak są one nadal takie same. Jeśli rozwiążesz równanie, znajdziesz Obszar B w Współczynniku Giniego jest taki sam jak Obszar B / Prob(Good) w Accuracy Ratio (co jest równoważne (1/2)*AR ). Mnożąc obie strony przez 2, otrzymasz Gini = 2*B i AR = Obszar B / (Obszar A + B)
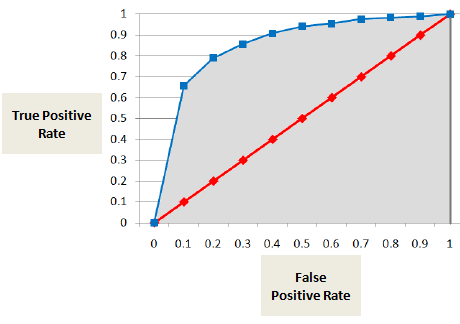
Area under ROC Curve (AUC)
AUC lub krzywa ROC pokazuje proporcję wyników prawdziwie pozytywnych (defaulter jest prawidłowo sklasyfikowany jako defaulter) w stosunku do proporcji wyników fałszywie pozytywnych (non-defaulter jest błędnie sklasyfikowany jako defaulter).
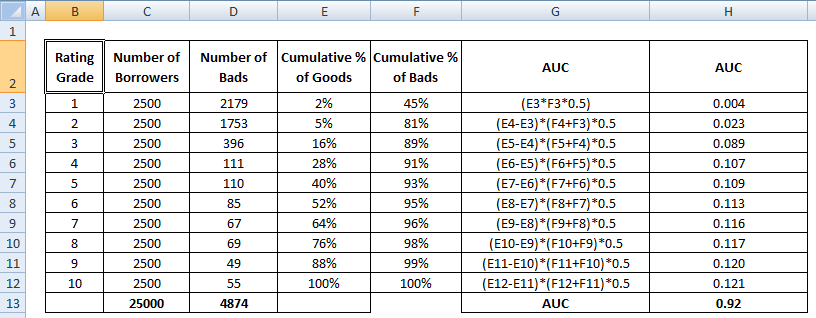
Wynik AUC jest sumą wszystkich indywidualnych wartości obliczonych na poziomie klasy ratingowej lub decyla.
4 Metody obliczania AUC Matematycznie
Zależność między AUC a współczynnikiem Giniego
Gini = 2*AUC – 1.
Musisz się zastanawiać, jak są one powiązane.
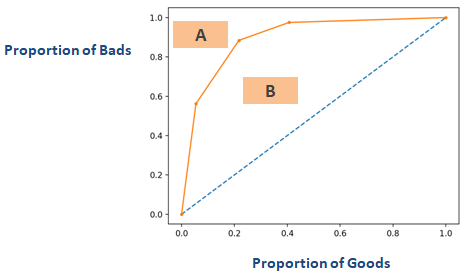
Jeśli odwrócisz oś wykresu pokazanego w powyższej sekcji o nazwie „Współczynnik Giniego”, otrzymasz wykres podobny do poniższego. Tutaj Gini = B / (A + B). Obszar A + B jest 0,5 więc Gini = B / 0,5 co upraszcza się do Gini = 2*B. AUC = B + 0.5, które dalej upraszcza się do B = AUC – 0,5. Wstaw to równanie do Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1
.