- Reverse Engineering Xero to Teach SQL
- Księgowość 101
- Wdrożenie Xero do rachunkowości
- Cykle transakcyjne
- Kontrola wewnętrzna
- Caveat: We’re Not Going Down The Rabbit Hole
- Podstawy bazy danych
- Prezentacja danych jest oddzielona od ich przechowywania.
- Tabele są zwykle połączone ze sobą w celu utworzenia relacji.
- Projektowanie naszej implementacji Xero
- Implementowanie naszej wersji w SQL
- Adding Contents to Our Database
- Tworzenie raportów finansowych z naszej bazy danych
- Hooray! Udało Ci się
Reverse Engineering Xero to Teach SQL
Scratch your own itch.
To jest rada, której zawsze udzielam, gdy ktoś mnie pyta, jak się nauczyć programowania. W praktyce oznacza to, że musisz rozwiązywać rzeczy lub wybierać projekty, które są dla Ciebie istotne – czy to w pracy, czy w życiu osobistym.
Bezmyślne oglądanie tutoriali na Youtube, czytanie książek o programowaniu, kopiowanie kodu z postów na Reddicie itp. zaprowadzi Cię donikąd, jeśli zaczynasz uczyć się programowania.
W tym poście pokażę Ci, jak zbudować surową bazę danych księgowych przy użyciu SQLite.
Więc, po co tworzyć bazę danych księgowych? Dlaczego po prostu nie skopiować danych publicznych, wrzucić je do SQLite i stamtąd ćwiczyć?
Powód jest taki, że tworzenie bazy danych księgowości jest wystarczająco zaawansowane, aby objąć wszystkie aspekty baz danych i SQL – od zapytań do złączeń do widoków i CTE.
Pochodząc z księgowości, myślę, że jest to najlepszy projekt do nauki SQL. Po tym wszystkim, programowanie jest narzędziem do rozwiązywania problemów. Stąd, równie dobrze można „rozwiązać” jakiś trudny, aby w pełni nauczyć się SQL.
Natchnienie do stworzenia systemu księgowego przy użyciu SQL dostałem obserwując jak działa Xero. Dla tych, którzy nie są zaznajomieni z nim, Xero jest oprogramowaniem księgowym w chmurze pochodzącym z Nowej Zelandii. Obecnie rozszerzył swoją działalność na Australię, USA, Kanadę i Wielką Brytanię.
Dobrą stroną Xero jest to, że ma ładny, czysty interfejs i wiele aplikacji do wyboru, aby rozszerzyć jego funkcjonalność.
Zastrzeżenie: Nie jestem inżynierem ani deweloperem w Xero i te obserwacje mogą nie odpowiadać dokładnie temu, jak działa system, ponieważ jest on zawsze aktualizowany. Z pewnością SQL przedstawiony tutaj nie jest dokładnym projektem SQL, którego używa Xero, ponieważ ich system musi się skalować. Ale jest to bardzo interesujący projekt, więc zróbmy to!
Księgowość 101
Zanim za bardzo się podekscytujesz, zróbmy sobie najpierw crash course na temat księgowości.
Podstawowe równanie rachunkowości to
Aktywa = Pasywa + Kapitał własny
To równanie ma zasadniczo trzy części
- Aktywa to wszystkie zasoby podmiotu.
- Pasywa to to, co firma jest winna.
- i Kapitał własny, akumulacja wszystkich inwestycji właściciela, rysunków, zysków lub strat.
Prawa strona opisuje, w jaki sposób aktywa zostały sfinansowane – albo przez pasywa lub kapitał własny.
Możemy rozwinąć powyższe równanie, aby rozbić kapitał własny
Aktywa = Pasywa + Kapitał początkowy + Przychody – Wydatki
Te 5 kont – Aktywa, Pasywa, Kapitał własny, Przychody, & Wydatki – są typami kont, które zazwyczaj widzimy w systemie księgowym.
Potem jest pojęcie Debetu i Kredytu. Mógłbym iść dalej i omówić te dwa dogłębnie, ale dla tego postu, wszystko, co musisz wiedzieć, że w każdej transakcji:
Debit = Credit
Te dwa równania ogólnie regulują to, co dzieje się w całym cyklu rachunkowości. Te dwa równania posłużą nam również jako przewodnik przy tworzeniu naszej własnej bazy danych księgowych.
Pochodząc ze środowiska księgowego, uważam, że jest to najlepszy projekt do nauki SQL. W końcu programowanie jest narzędziem do rozwiązywania problemów. Stąd, równie dobrze można „rozwiązać” jakiś trudny, aby w pełni nauczyć się SQL.
Wdrożenie Xero do rachunkowości
Ważną rzeczą, o której należy pamiętać jest to, że Xero jest zaprojektowane w taki sposób, aby było przydatne właścicielom firm (nie księgowym) w codziennej działalności przedsiębiorstwa.
Jako taki, został zaprojektowany wokół cykli transakcji i kontroli wewnętrznej.
Cykle transakcyjne
Podstawowe cykle transakcyjne są następujące
- Cykle sprzedaży
- Cykle zakupów
- Cykle kasowe
Xero implementuje te cykle w następujący sposób
Cykle sprzedaży
Sprzedaże są wprowadzane do Xero za pomocą Faktur. Wyobraź sobie, że firma wystawia rzeczywiste faktury papierowe za sprzedaż (sprzedaż gotówkową lub na rachunek). Jest to dokładna rzecz, którą Xero chce odtworzyć.
Faktury można drukować bezpośrednio z oprogramowania i są one automatycznie numerowane w kolejności rosnącej.
Pod maską, faktury zwiększają konto sprzedaży i konto należności (AR).
Cykl Zakupów
Faktury są wprowadzane do Xero za pomocą Rachunków. Ponownie, wyobraź sobie firmę, która wystawia rzeczywiste rachunki za zakupy (zakupy gotówkowe lub na rachunek). Jest to typowy przypadek dla usług komunalnych i inwentaryzacji. Jest to również rzecz, którą Xero chce replikować.
Faktury mogą być drukowane bezpośrednio z oprogramowania i mogą być wykorzystywane do uzupełnienia wszelkich procedur zatwierdzania wykonanych przez firmę.
Pod maską, rachunki zwiększają konto zakupów i konto Accounts Payable (AP).
Cash Cycle
To obejmuje wszystkie transakcje odnoszące się do gotówki. Istnieją 4 rodzaje
- Invoice Payments – płatności za zaległe faktury
- Bill Payments – płatności za zaległe rachunki
- Received Money – wpływy gotówkowe, które nie są płatnościami za faktury. Może to dotyczyć sprzedaży gotówkowej, ale jeśli zamierzasz wystawić fakturę, użyj funkcji Faktury.
- Wydane pieniądze – wydatki gotówkowe, które nie są płatnościami za rachunki. Może to obejmować zakupy gotówkowe, ale jeśli zamierzasz wystawić rachunek, użyj funkcji Rachunki.
To jest część dotycząca cykli transakcji.
Kontrola wewnętrzna
Dla kontroli wewnętrznej, musisz zrozumieć koncepcję kont systemowych.
Xero ma obszerny artykuł dotyczący zrozumienia kont systemowych tutaj. Ale dla naszych celów omówimy tylko następujące konta systemowe
- Konta należności
- Konta do zapłaty
- Konta bankowe (powiązane z Bank Feeds)
Konta te nie mogą być używane w Dziennikach ręcznych. Oznacza to, że Xero chce, abyś korzystał z Faktur, Rachunków i Transakcji Gotówkowych (Płatności Faktur, Płatności Rachunków, Otrzymanych Pieniędzy i Wydanych Pieniędzy) w celu wsparcia salda tych kont. Jest to implementacja kontroli wewnętrznej Xero, jeśli chcesz.
Oczywiście, możesz użyć niesystemowej wersji kont AR, AP i Bank, tworząc je w Planie kont (COA). Nie można jednak używać dla nich typów kont AR, AP i Bank.
Ważną rzeczą do zapamiętania jest to, że Xero jest zaprojektowane w taki sposób, aby było przydatne właścicielom firm (a nie księgowym) w codziennej działalności biznesowej.
Caveat: We’re Not Going Down The Rabbit Hole
Projektowanie księgowości jest naprawdę skomplikowane. Potrzeba wielu wpisów na blogu, aby pokryć ten temat. Stąd, dla uproszczenia, będziemy tworzyć następujące założenia (nie dokładnie jak Xero implementuje te)
- Płatności faktur i rachunków
Płatności fakturowe mogą płacić dwie lub więcej faktur w całości. Oznacza to, że nie pozwolimy na częściowe płatności. To samo dotyczy płatności za rachunki. - Inwentaryzacja
Nie będziemy tutaj używać pozycji inwentaryzacji. W przypadku sprzedaży lub zakupu będziemy korzystać bezpośrednio z konta Inventory, zamiast tworzyć pozycje inwentaryzacyjne, które będą mapowane na konto Inventory.
To tyle jeśli chodzi o nasze założenia. Po zaprojektowaniu naszej bazy danych czytelnik może znieść te założenia i spróbować naśladować Xero tak bardzo, jak to tylko możliwe.
Podstawy bazy danych
Teraz, zanim odtworzymy naszą wersję struktury bazy danych Xero, zróbmy sobie krótki kurs na temat baz danych.
Baza danych jest zbiorem tabel. Każda tabela składa się z wierszy danych zwanych rekordami. Kolumny są nazywane polami.
Program do pracy z bazą danych jest nazywany Systemem Zarządzania Bazą Danych lub DBMS. Jako prosta analogia, DBMS to program Excel, baza danych to skoroszyt Excel, a tabela to arkusz Excel.
Istnieją dwie główne różnice między bazą danych a skoroszytem Excel.
Prezentacja danych jest oddzielona od ich przechowywania.
To znaczy, że nie można edytować danych w bazie danych, przechodząc bezpośrednio do danych i edytując je. (Inne programy DBMS mają GUI, które pozwalają na bezpośredni dostęp do danych w bazie danych i edytowanie ich jak w arkuszu kalkulacyjnym. Ale pod maską, ta akcja wydaje polecenie SQL).
Tabele są zwykle połączone ze sobą w celu utworzenia relacji.
Relacje mogą być jeden do jednego, jeden do wielu lub wiele do wielu.
Relacja jeden do jednego oznacza „wiersz tabeli jest związany tylko z jednym wierszem w innej tabeli i na odwrót”. Przykładem może być powiązanie nazwiska pracownika z numerem identyfikacji podatkowej.
Ten rodzaj jest zazwyczaj zawarty w jednej tabeli Pracownicy, ponieważ naprawdę nie ma korzyści z rozdzielenia danych do dwóch tabel.
Jeden do wielu z drugiej strony oznacza „wiersz tabeli jest powiązany tylko z jednym lub więcej wierszy w innej tabeli, ale nie odwrotnie”. Przykładem jest powiązanie faktur z InvoiceLines. Faktura może mieć wiele wierszy, ale wiersz faktury należy tylko do konkretnej faktury.
I jak można się domyślić, many-to-many oznacza „wiersz tabeli jest powiązany tylko z jednym lub wieloma wierszami w innej tabeli i na odwrót”. Przykładem może być system, który implementuje częściowe płatności.
Faktura może być zapłacona częściowo przez różne transakcje płatności, a płatność może zapłacić częściowo różne faktury.
Jak baza danych zna te relacje?
To proste. To przez użycie kluczy głównych i obcych.
Klucze główne są niezbędne do odróżnienia jednego wiersza od drugiego. Unikalnie identyfikują one każdy wiersz danych w tabeli.
Klucze obce, z drugiej strony, są kluczami podstawowymi z innej tabeli. Stąd, poprzez odniesienie kluczy podstawowych i obcych, relacje w bazie danych są utrzymywane.
Dla jeden do wielu, strona „jeden” zawiera klucz podstawowy, a „wiele” zawiera ten podstawowy jako klucz obcy. W naszym powyższym przykładzie, aby uzyskać wszystkie wiersze należące do faktury, pytamy tabelę InvoiceLines, gdzie klucz obcy jest równy konkretnemu numerowi faktury.
Dla wielu do wielu, relacja jest rozbita na dwie relacje jeden do wielu poprzez użycie trzeciej tabeli zwanej tabelą „łączącą”. Na przykład, nasz system płatności częściowych będzie miał tabelę Faktury, tabelę Płatności i tabelę FakturaPłatności jako tabelę łączącą. Kluczami podstawowymi tabeli InvoicePayments będzie klucz złożony składający się z kluczy podstawowych dla tabeli Invoices i Payments w następujący sposób

.
Zwróć uwagę, że tabela łączenia nie zawiera żadnych innych danych, ponieważ nie ma żadnego innego celu poza połączeniem tabel Faktury i Płatności.
Aby uzyskać faktury zapłacone przez pewną transakcję płatniczą, powiedzmy PAY 1, łączymy tabele Faktury i Płatności poprzez tabelę łączącą i pytamy o payment_id = "PAY 1".
To tyle, jeśli chodzi o podstawy bazy danych. Teraz jesteśmy gotowi do zaprojektowania naszej bazy danych.
Jako prosta analogia, DBMS to program Excel, baza danych to skoroszyt Excela, a tabela to arkusz Excela.
Projektowanie naszej implementacji Xero
Teraz, gdy mamy już podstawowe zrozumienie Xero, możemy zacząć tworzyć szkic jego struktury bazy danych. Zwróć uwagę, że zamierzam użyć formatu Table_Name. Czyli słowa pisane wielką literą, oddzielone od siebie podkreślnikami. Będę również używał nazw tabel w liczbie mnogiej.
Dla Cyklu Sprzedaży, będziemy mieli następujące tabele
- Faktury
- Klienci – klient może mieć wiele faktur, ale faktura nie może należeć do wielu klientów
- Faktury_Płatności – pamiętaj o naszym założeniu, że istnieje relacja jeden do wielu pomiędzy Faktury_Płatności i Faktury odpowiednio (nie ma częściowych płatności)
- Faktury_Linie – jest to tabela łącząca Faktury i COA. Konto może występować w wielu fakturach, a faktura może mieć wiele kont.
- Chart of Accounts (COA)
Dla Cyklu Zakupów, będziemy mieli następujące tabele
- Bills
- Suppliers – dostawca może mieć wiele rachunków, ale rachunek nie może należeć do wielu dostawców
- Bill_Payments – pamiętaj o naszym założeniu, że istnieje relacja jeden do wielu pomiędzy Bill_Payments i rachunkami
- Bill_Lines – jest to tabela łącząca rachunki i COA. Rachunek może występować w wielu rachunkach, a rachunek może mieć wiele rachunków.
- COA – to samo z powyższym w Cyklu Sprzedaży. Wstawiam tutaj tylko dla uzupełnienia.
Dla Cyklu Gotówkowego, będziemy mieli następujące tabele (tabele płatności, które już utworzyliśmy powyżej)
- Received_Moneys – może mieć opcjonalnego Klienta
- Received_Money_Lines – jest to tabela łącząca tabela łącząca Received_Moneys i COA
- Spent_Moneys – może mieć opcjonalnie Supplier
- Spent_Money_Lines – jest to tabela łącząca Spent_Moneys i COA
Koncepcyjnie, struktura naszej bazy danych wygląda następująco
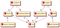
Diagram ten nazywany jest diagramem relacji encji (Entity-Relationship Diagram) lub ERD w języku baz danych. Relacje jeden do wielu są oznaczane przez 1 – M, a wiele do wielu przez M – M.
Tabele łączące nie są pokazane na powyższym diagramie, ponieważ są one implicite w tabelach z relacjami wiele do wielu.
Implementowanie naszej wersji w SQL
Teraz nadszedł czas, aby zaimplementować nasz model w SQL. Zacznijmy od zdefiniowania pewnych konwencji.
Klucz główny będzie miał pole/kolumnę o nazwie id, a klucz obcy będzie miał format table_id, gdzie table jest nazwą tabeli po stronie „wielu” w liczbie pojedynczej. Na przykład, w tabeli Faktury, klucz obcy będzie miał postać customer_id.
Czas dla kodu SQL. Oto on.
Kilka rzeczy tutaj:
- W poleceniach SQL nie jest rozróżniana wielkość liter,
CREATE TABLEjest takie samo jakcreate table - Kod
IF EXISTSiIF NOT EXISTSsą opcjonalne. Używam ich tylko po to, aby zapobiec błędom w moich poleceniach SQL. Na przykład, jeśli upuszczę nieistniejącą tabelę, SQLite poda błąd. Umieściłem równieżIF NOT EXISTSna poleceniu create table, abyśmy przypadkowo nie nadpisali żadnej istniejącej tabeli. - Bądź ostrożny z poleceniem
DROP TABLE! Usunie ono istniejącą tabelę bez ostrzeżenia, nawet jeśli ma ona zawartość. - Nazwy tabel mogą być również pisane wielkimi literami lub nie. Jeśli nazwy tabel zawierają spacje, powinny być otoczone backtickiem (`). Nie jest rozróżniana wielkość liter.
SELECT * FROM Customersjest takie samo jakselect * from customers.
Mimo że SQL jest nieco luźny pod względem składni, powinieneś dążyć do zachowania spójności w swoim kodzie SQL.
Zwróć również uwagę na relacje pokazane w powyższym ERD. Pamiętaj również, że klucz obcy jest po stronie wielu.
Porządek jest ważny, ponieważ niektóre tabele służą jako zależność do innej z powodu klucza obcego. Na przykład musisz utworzyć najpierw tabelę Faktury_Płatności przed tabelą Faktury, ponieważ ta pierwsza jest zależna od tej drugiej. Sztuczka polega na tym, aby zacząć od krawędzi ERD, ponieważ są to te, które mają najmniejszą liczbę kluczy obcych.
Możesz również pobrać przykładową bazę danych w SQLite bez zawartości w tym linku.
Aby ją wyświetlić, możesz użyć darmowej i otwartej przeglądarki SQLite Browser. Pobierz ją tutaj!
Adding Contents to Our Database
Teraz, gdy mamy już przykładową bazę danych, wprowadźmy do niej dane. Przykładowe dane można pobrać stąd – po prostu podziel je na CSV według potrzeb.
Zwróć uwagę, że kredyty są pokazywane jako pozytywy, a kredyty jako negatywy.
Dla tego postu, po prostu użyłem funkcji importu DB Browser, aby zaimportować CSV z powyższego pliku Excel. Na przykład, aby zaimportować Customers.csv
- Wybierz tabelę Customers
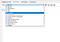
- Przejdź do Plik > Import > Tabela z pliku CSV i wybierz Customers.csv
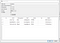
- Kliknij Ok/Tak na wszystkie kolejne monity, aby zaimportować dane.
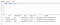
Jeśli wydasz następujące polecenie SQL, powinno ono wyświetlić wszystkich Klientów w naszej bazie danych
Tworzenie raportów finansowych z naszej bazy danych
Aby udowodnić, że nasza baza danych działa jako surowy system księgowy, stwórzmy Bilans Próbny.
Pierwszym krokiem jest utworzenie widoków transakcji dla naszych transakcji Invoices, Bills, Received_Moneys i Spent_Moneys. Kod będzie wyglądał następująco
W pierwszych dwóch instrukcjach, używam CTE (ze słowem kluczowym recursive). CTE są użyteczne, ponieważ łączę 4 tabele, aby uzyskać jeden widok dla transakcji faktur i odpowiadających im płatności. Możesz dowiedzieć się więcej o CTE w SQLite tutaj.
Po wykonaniu powyższego polecenia, twoja baza danych powinna mieć następujące 4 widoki.
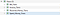
Na koniec, tworzymy kod dla Bilansu Próbnego lub w skrócie TB. Zauważ, że TB to po prostu zbiór sald naszych transakcji z uwzględnieniem reguł, które ustaliliśmy projektując naszą bazę danych.
Kod wygląda następująco
Powyższy kod zawiera wiele zapytań SQL połączonych poleceniem union all. Opatrzyłem każde zapytanie adnotacją, aby pokazać, co każde z nich próbuje osiągnąć.
Na przykład, pierwsze zapytanie próbuje uzyskać wszystkie kredyty dla transakcji Faktury (głównie Sprzedaż). Drugie dla debetów transakcji Rachunków (głównie Zakupów) i tak dalej.
Wykonanie tego powinno skutkować następującym TB.
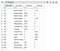
Możesz umieścić to w Excelu, aby sprawdzić, czy debety są równe kredytom (co zrobiłem). Suma debetów i kredytów wynosi odpowiednio 14115 i -14115.
Hooray! Udało Ci się
Tworzenie systemu księgowego jest naprawdę skomplikowane. Zasadniczo zbadaliśmy całą gamę projektowania bazy danych – od koncepcji, przez ERD, po tworzenie i odpytywanie. Poklep się po plecach za dotarcie tak daleko.
Zauważ, że celowo ograniczyliśmy naszą bazę danych, aby skupić się bardziej na koncepcjach. Możesz podnieść je i spróbować zbudować inną bez ograniczeń.
To jest to! Jesteś teraz SQL-owym ninja! Gratulacje!
Check out my second book Accounting Database Design soon to be published on Leanpub!
Sprawdź również moją pierwszą książkę PowerQuery Guide to Pandas na Leanpub.
Śledź mnie na Twitterze i Linkedin.