Cumulative Accuracy Profile (CAP)
Cumulative Accuracy Profile (CAP) de um modelo de classificação de crédito mostra a percentagem de todos os mutuários (devedores) no eixo x e a percentagem de inadimplentes (maus clientes) no eixo y. Na análise de marketing, é chamado deGain Chart. Também é chamado de Power Curve em alguns outros domínios.
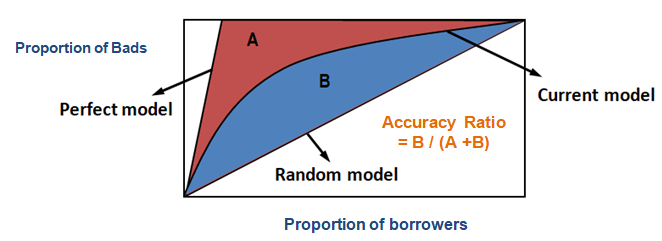
Usando CAP, você pode comparar a curva do seu modelo atual com a curva do modelo ‘ideal ou perfeito’ e também pode compará-la com a curva do modelo aleatório. O ‘modelo perfeito’ refere-se ao estado ideal no qual todos os maus clientes (resultado desejado) podem ser capturados diretamente. O ‘modelo aleatório’ refere-se ao estado em que a proporção de maus clientes é distribuída igualmente. O ‘Modelo atual’ refere-se à sua probabilidade de modelo padrão (ou qualquer outro modelo em que você esteja trabalhando). Nós sempre tentamos construir o modelo que se inclina para (mais próximo) da curva do modelo perfeito. Podemos ler o modelo atual como ‘% de maus clientes cobertos em um determinado nível de decile’. Por exemplo, 89% dos clientes maus capturados apenas selecionando 30% dos devedores do topo com base no modelo.
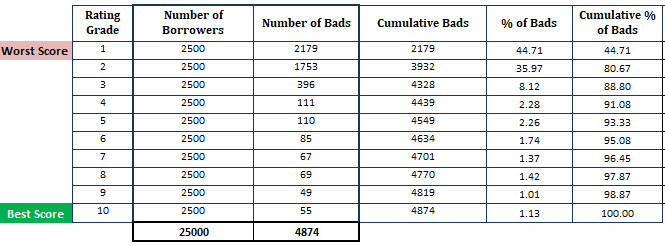
- Selecionar a probabilidade estimada de padrão em ordem decrescente e dividi-la em 10 partes (decilo). Isso significa que os mutuários de maior risco com PD elevado devem estar no decil superior e os mutuários mais seguros devem aparecer no decil inferior. Dividir a pontuação em 10 partes não é uma regra de decilo. Em vez disso, você pode usar a nota de classificação.
- Calcular número de devedores (observações) em cada decil
- Calcular número de maus clientes em cada decil
- Calcular número cumulativo de maus clientes em cada decil
- Calcular percentagem de maus clientes em cada decil
- Calcular percentagem acumulada de maus clientes em cada decil
Até agora, fizemos cálculos baseados no modelo de DP (Lembre-se que o primeiro passo é baseado nas probabilidades obtidas a partir do modelo de DP).
Próximo passo : Qual deve ser o número de clientes maus em cada decil baseado no modelo perfeito?
- No modelo perfeito, First decile deve capturar todos os clientes maus como primeiro decil refere-se ao pior grau de classificação OU aos mutuários com maior probabilidade de incumprimento. No nosso caso, First decile não pode capturar todos os maus clientes, pois o número de devedores que caem no primeiro decil é menor do que o número total de maus clientes.
- Calcular o número cumulativo de maus clientes em cada decil com base no modelo perfeito
- Calcular a percentagem cumulativa de maus clientes em cada decil com base no modelo perfeito
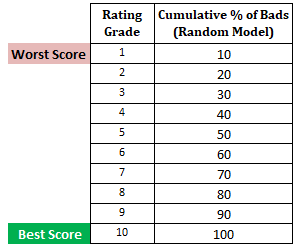
Passo seguinte: Calcular a percentagem cumulativa de maus clientes em cada decil com base no modelo aleatórioNo modelo aleatório, cada decil deve constituir 10%. Quando calculamos a % acumulada, será 10% no decil 1, 20% no decil 2 e assim sucessivamente até 100% no decil 10.
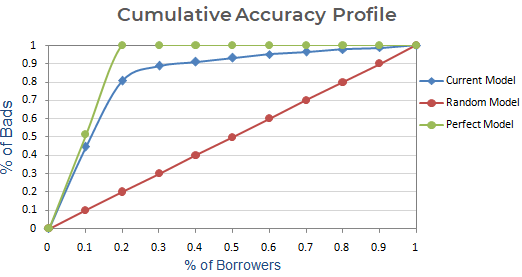
Passo seguinte : Criar um gráfico com a % acumulada de clientes com base no Modelo Actual, Aleatório e Perfeito. No eixo x, mostra a percentagem de devedores (observações) e o eixo y representa a percentagem de maus clientes.
Rácio de Precisão
No caso do CAP (Cumulative Accuracy Profile), o rácio de Precisão é o rácio da área entre o seu modelo preditivo actual e a linha diagonal e a área entre o modelo perfeito e a linha diagonal. Em outras palavras, é a razão entre a melhoria do desempenho do modelo atual sobre o modelo aleatório e a melhoria do desempenho do modelo perfeito sobre o modelo aleatório.
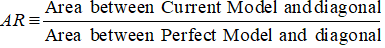
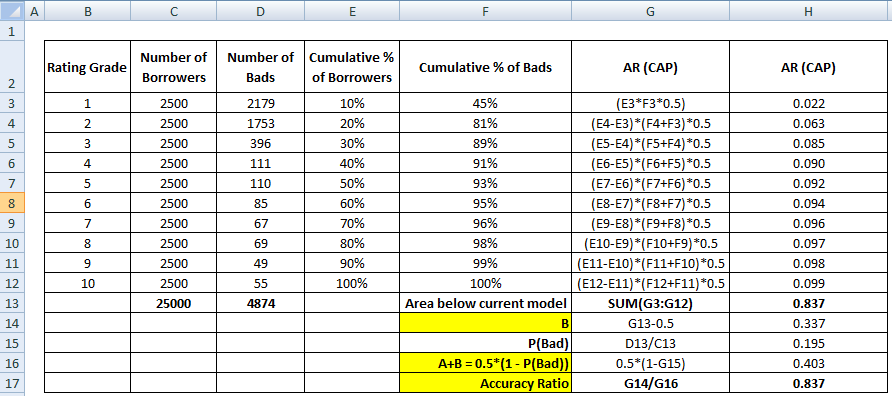
Primeiro passo é calcular a área entre o modelo atual e a linha diagonal. Podemos calcular a área abaixo do modelo atual (incluindo a área abaixo da linha diagonal) usando o método de Integração Numérica da Regra Trapezoidal. A área de um trapézio é
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) é a largura do subintervalo e (yi + yi+1)*0,5 é a altura média.
Neste caso, x refere-se a valores da proporção acumulada de devedores em diferentes níveis de decilo e y refere-se a proporção acumulada de maus clientes em diferentes níveis de decilo. O valor de x0 e y0 é 0,
O passo acima é completado, o próximo passo é subtrair 0,5 da área devolvida do passo anterior. Você deve estar se perguntando a relevância de 0,5. É a área abaixo da linha diagonal. Estamos subtraindo porque só precisamos de área entre o modelo atual e a linha diagonal (vamos chamá-la de B).
Agora precisamos do denominador que é a área entre o modelo perfeito e a linha diagonal, A + B. É equivalente a 0.5*(1 - Prob(Bad)). Veja todos os passos de cálculo mostrados na tabela abaixo –
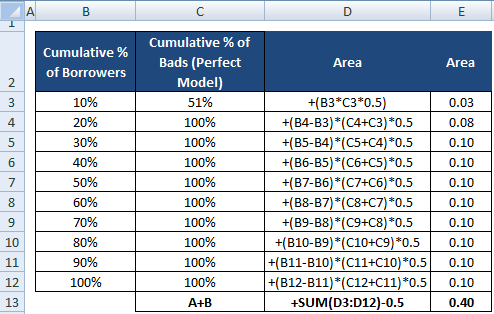
Denominador do RA também pode ser computado como fizemos o cálculo para o numerador. Isso significa calcular a área usando “Cumulative % of Borrowers” e “Cumulative % of Bads (Perfect Model)” e depois subtraindo 0,5 dele, já que não precisamos considerar área abaixo da linha diagonal.
No código R abaixo, nós preparamos dados de amostra, por exemplo. O nome da variável pred refere-se às probabilidades previstas. Variável y refere-se a variável dependente (evento real). Só precisamos dessas duas variáveis para calcular a Relação de Precisão.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
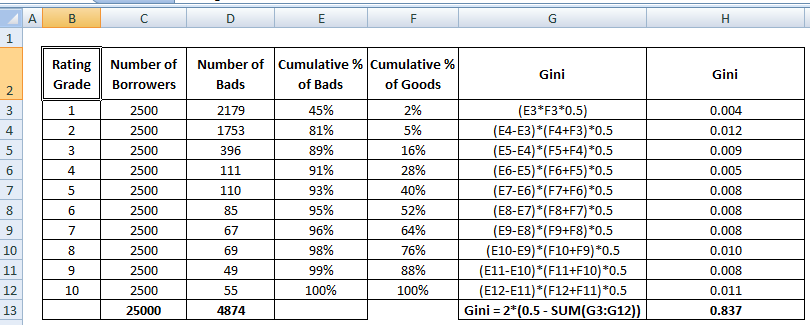
Coeficiente de Gini
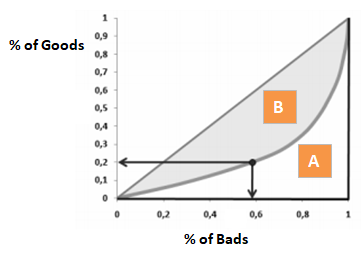
O coeficiente de Gini é muito semelhante ao CAP, mas mostra proporção (cumulativa) de bons clientes ao invés de todos os clientes. Ele mostra até que ponto o modelo tem melhores capacidades de classificação em comparação com o modelo aleatório. Também é chamado de Índice de Gini. O Coeficiente de Gini pode tomar valores entre -1 e 1. Valores negativos correspondem a um modelo com significados invertidos de pontuação.
Gini = B / (A+B). Ou Gini = 2B já que a Área de A + B é 0,5
Veja os passos de cálculo do Coeficiente de Gini abaixo :
Rejeitando x% de bons clientes, qual a porcentagem de maus clientes que rejeitamos ao lado.
Coeficiente de Gini é um caso especial da estatística D de Somer. Se você tiver concordância e discordância percentual, você pode calcular o Coeficiente de Gini.
Gini Coefficient = (Concordance percent – Discordance Percent)
Porcentagem de concordância refere-se à proporção de pares onde os inadimplentes têm uma probabilidade prevista maior do que os bons clientes.
Porcentagem de discordância refere-se à proporção de pares onde os inadimplentes têm uma probabilidade prevista menor do que os bons clientes.
Outra forma de calcular o Coeficiente de Gini é usar a porcentagem de concordância e discordância (como explicado acima). Consulte o código R abaixo.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Are Gini Coeficiente e Relação de Precisão equivalentes?
Sim, eles são sempre iguais. Portanto, o Coeficiente de Gini é às vezes chamado de Relação de Precisão (RA).
Sim, eu sei que os eixos em Gini e RA são diferentes. Surge a questão de como eles ainda são iguais. Se você resolver a equação, você encontrará a Área B no Coeficiente de Gini é igual à Área B / Prob(Bom) na Relação de Precisão (que é equivalente a (1/2)*AR ). Multiplicando ambos os lados por 2, você obterá Gini = 2*B e AR = Área B / (Área A + B)
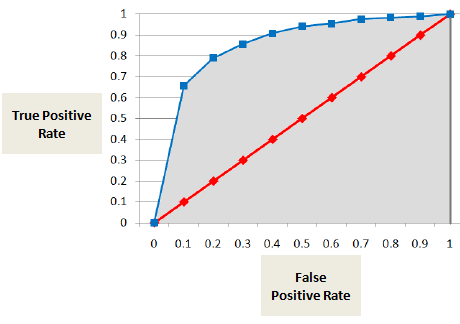
Área sob Curva ROC (AUC)
AUC ou curva ROC mostra a proporção de verdadeiros positivos (o inadimplente é corretamente classificado como inadimplente) versus a proporção de falsos positivos (o inadimplente é erroneamente classificado como inadimplente).
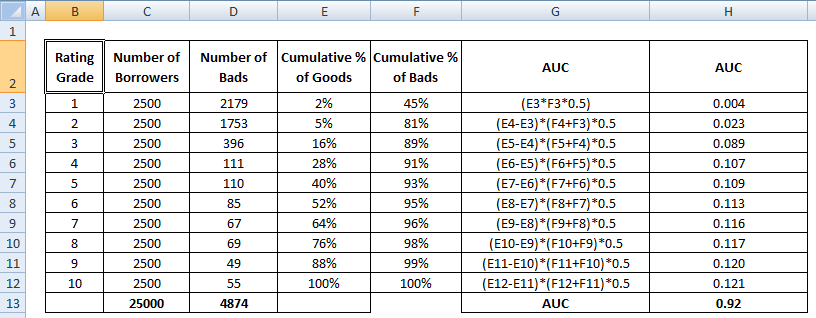
AUC score é a soma de todos os valores individuais calculados em grau de classificação ou nível de decile.
4 Métodos para calcular matematicamente a AUC
Relação entre a AUC e o Coeficiente de Gini
Gini = 2*AUC – 1.
Você deve estar se perguntando como eles estão relacionados.
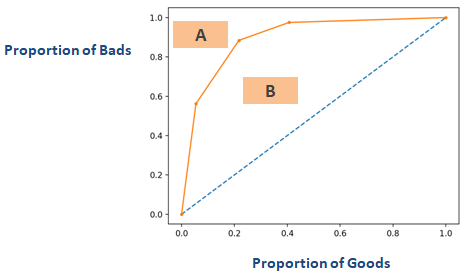
Se você inverter o eixo do gráfico mostrado na seção acima chamada “Coeficiente de Gini”, você obteria similar ao gráfico abaixo. Aqui Gini = B / (A + B). A área de A + B é 0,5 então Gini = B / 0,5 o que simplifica para Gini = 2*B. AUC = B + 0.5 o que simplifica ainda mais para B = AUC – 0,5. Coloque esta equação em Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1
.