Cumulative Accuracy Profile (CAP)
Cumulative Accuracy profile (CAP) a unui model de rating de credit arată procentul tuturor împrumutaților (debitori) pe axa x și procentul de neplătitori (clienți neperformanți) pe axa y. În analiza de marketing, se numeșteGain Chart. În alte domenii se mai numește și Curba de putere.
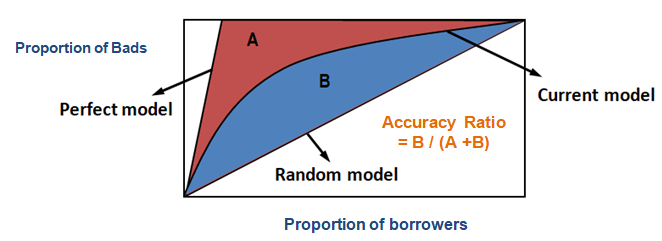
Cu ajutorul PAC, puteți compara curba modelului dvs. actual cu curba modelului „ideal sau perfect” și o puteți compara, de asemenea, cu curba unui model aleatoriu. ‘Modelul perfect’ se referă la starea ideală în care toți clienții răi (rezultatul dorit) pot fi capturați direct. ‘Modelul aleatoriu’ se referă la starea în care proporția de clienți răi este distribuită în mod egal. ‘Modelul actual’ se referă la modelul dvs. de probabilitate de neplată (sau orice alt model la care lucrați). Încercăm întotdeauna să construim modelul care se înclină spre (mai aproape) de curba modelului perfect. Putem citi modelul actual ca „% de clienți rău-platnici acoperiți la un anumit nivel de decil”. De exemplu, 89% din clienții rău-platnici acoperiți doar prin selectarea primilor 30% din debitori pe baza modelului.
- Sortați probabilitatea estimată de neplată în ordine descrescătoare și împărțiți-o în 10 părți (decile). Aceasta înseamnă că cei mai riscanți împrumutați cu PD mare ar trebui să se afle în decilul superior, iar cei mai siguri împrumutați ar trebui să apară în decilul inferior. Împărțirea scorului în 10 părți nu este o regulă empirică. În schimb, puteți utiliza gradul de rating.
- Calculați numărul de împrumutați (observații) din fiecare decilă
- Calculați numărul de clienți rău-platnici din fiecare decilă
- Calculați numărul cumulat de clienți rău-platnici din fiecare decilă
- Calculează procentul de clienți rău-platnici din fiecare decil
- Calculează procentul cumulat de clienți rău-platnici din fiecare decil
.
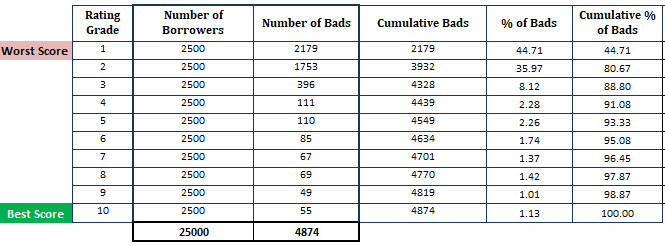
Până acum, am efectuat calculele pe baza modelului PD (Rețineți că prima etapă se bazează pe probabilitățile obținute din modelul PD).
Pasul următor: Care ar trebui să fie numărul de clienți rău-platnici din fiecare decilă pe baza modelului perfect?
- În modelul perfect, primul decil ar trebui să cuprindă toți clienții rău-platnici, deoarece primul decil se referă la cel mai prost grad de rating SAU la debitorii cu cea mai mare probabilitate de neplată. În cazul nostru, prima decilă nu poate cuprinde toți clienții rău-platnici, deoarece numărul de debitori care se încadrează în prima decilă este mai mic decât numărul total de clienți rău-platnici.
- Calculați numărul cumulat de clienți rău-platnici din fiecare decilă pe baza modelului perfect
- Calculați procentul cumulat de clienți rău-platnici din fiecare decilă pe baza modelului perfect

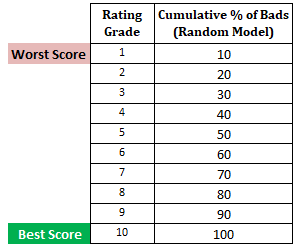
Pasul următor: Calculați procentul cumulat de clienți rău-platnici din fiecare decilă pe baza modelului aleatoriuÎn modelul aleatoriu, fiecare decilă ar trebui să constituie 10%. Când calculăm procentul cumulativ, acesta va fi de 10% în decilul 1, 20% în decilul 2 și așa mai departe până la 100% în decilul 10.
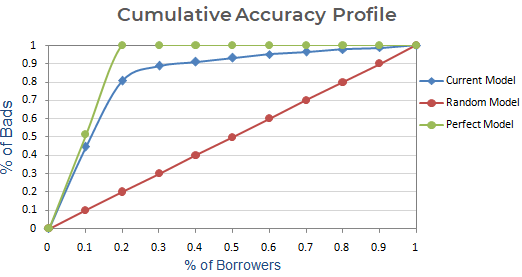
Pasul următor : Creați un grafic cu procentul cumulativ de clienți răi pe baza modelului curent, aleatoriu și perfect. Pe axa x, se arată procentul de împrumutați (observații), iar axa y reprezintă procentul de clienți rău-platnici.
Raportul de acuratețe
În cazul CAP (Cumulative Accuracy Profile), raportul de acuratețe este raportul dintre zona dintre modelul dvs. predictiv actual și linia diagonală și zona dintre modelul perfect și linia diagonală. Cu alte cuvinte, este raportul dintre îmbunătățirea performanței modelului actual față de modelul aleatoriu și îmbunătățirea performanței modelului perfect față de modelul aleatoriu.
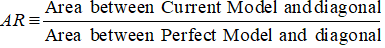
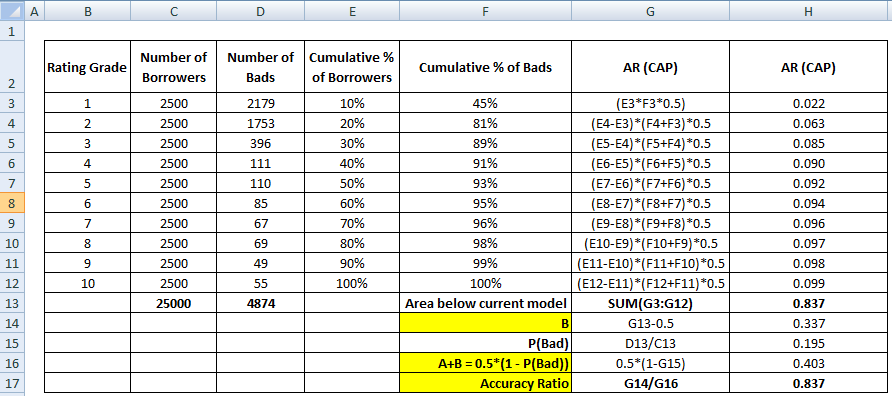
Primul pas este să calculați aria dintre modelul actual și linia diagonală. Putem calcula zona de sub modelul curent (inclusiv zona de sub linia diagonală) folosind metoda de integrare numerică Trapezoidal Rule Numerical Integration. Aria unui trapez este
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) este lățimea subintervalului, iar (yi + yi+1)*0,5 este înălțimea medie.
În acest caz, x se referă la valorile proporției cumulate a debitorilor la diferite niveluri ale decilului și y se referă la proporția cumulată a clienților rău-platnici la diferite niveluri ale decilului. Valoarea lui x0 și y0 este 0.
După ce pasul de mai sus este finalizat, următorul pas este de a scădea 0,5 din suprafața obținută la pasul anterior. Trebuie să vă întrebați care este relevanța lui 0,5. Este suprafața de sub linia diagonală. Scădem pentru că avem nevoie doar de suprafața dintre modelul actual și linia diagonală (să o numim B).
Acum avem nevoie de numitor, care este suprafața dintre modelul perfect și linia diagonală, A + B. Acesta este echivalent cu 0.5*(1 - Prob(Bad)). Vedeți toate etapele de calcul prezentate în tabelul de mai jos –
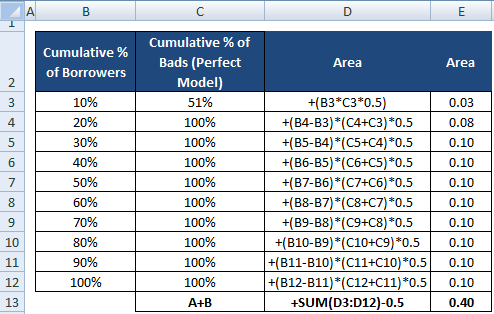
Dominatorul lui AR poate fi, de asemenea, calculat așa cum am efectuat calculul pentru numărător. Aceasta înseamnă să calculăm aria folosind „Cumulative % of Borrowers” și „Cumulative % of Bads (Perfect Model)” și apoi să scădem 0,5 din ea, deoarece nu trebuie să luăm în considerare aria de sub linia diagonală.
În codul R de mai jos, am pregătit date de probă pentru exemplu. Numele variabilei pred se referă la probabilitățile prezise. Variabila y se referă la variabila dependentă (evenimentul real). Avem nevoie doar de aceste două variabile pentru a calcula Accuracy Ratio.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
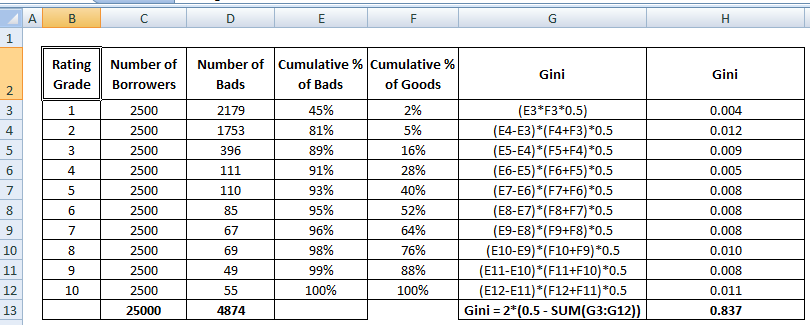
Coeficientul Gini
Coeficientul Gini este foarte asemănător cu CAP, dar arată proporția (cumulativă) de clienți buni în loc de toți clienții. Acesta arată măsura în care modelul are capacități de clasificare mai bune în comparație cu modelul aleatoriu. Se mai numește și indicele Gini. Coeficientul Gini poate lua valori între -1 și 1. Valorile negative corespund unui model cu semnificații inversate ale scorurilor.
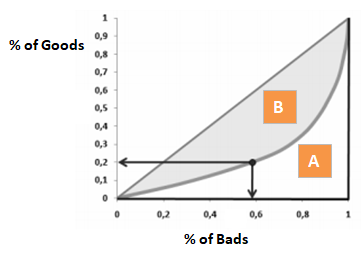
Gini = B / (A+B). Sau Gini = 2B, deoarece aria lui A + B este 0,5
Vezi mai jos etapele de calcul ale coeficientului Gini :
Respingând x% din clienții buni, ce procent de clienți răi respingem alături.
Coeficientul Gini este un caz special al statisticii D a lui Somer. Dacă aveți procente de concordanță și discordanță, puteți calcula coeficientul Gini.
Gini Coefficient = (Concordance percent - Discordance Percent)Procentul de concordanță se referă la proporția de perechi în care restanțierii au o probabilitate prezisă mai mare decât clienții buni.
Procentul de discordanță se referă la proporția de perechi în care restanțierii au o probabilitate prezisă mai mică decât clienții buni.
Un alt mod de a calcula coeficientul Gini este folosind concordanța și procentul de discordanță (așa cum s-a explicat mai sus). Consultați codul R de mai jos.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Este coeficientul Gini și rata de precizie echivalente?
Da, acestea sunt întotdeauna egale. Prin urmare, coeficientul Gini este uneori numit coeficient de precizie (AR).
Da, știu că axele din Gini și AR sunt diferite. Se pune întrebarea cum de ele sunt în continuare aceleași. Dacă rezolvați ecuația, veți descoperi că Aria B din Coeficientul Gini este aceeași cu Aria B / Prob(Bun) din Raportul de Precizie (care este echivalent cu (1/2)*AR ). Înmulțind ambele părți cu 2, veți obține Gini = 2*B și AR = Suprafața B / (Suprafața A + B)
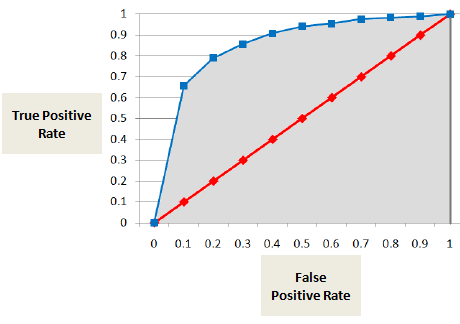
Arie sub curba ROC (AUC)
AUC sau curba ROC arată proporția de adevărați pozitivi (persoana rău-platnică este clasificată corect ca fiind rău-platnică) față de proporția de falși pozitivi (persoana care nu este rău-platnică este clasificată greșit ca fiind rău-platnică).
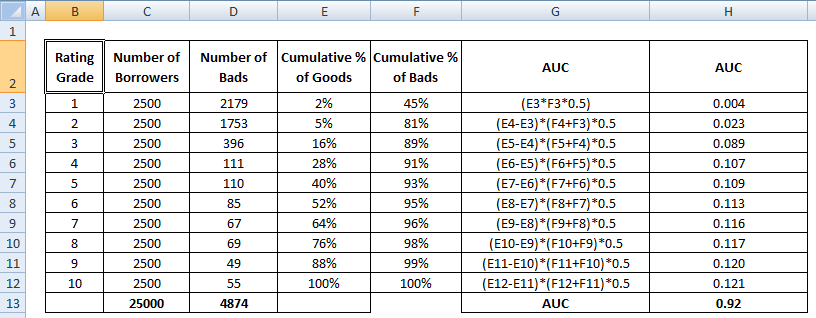
Scorul AUC este suma tuturor valorilor individuale calculate la nivelul gradului de clasificare sau al decilului.
4 Metode de calcul al AUC Matematic
Relația dintre AUC și coeficientul Gini
Gini = 2*AUC – 1.
Trebuie să vă întrebați cum sunt legate.
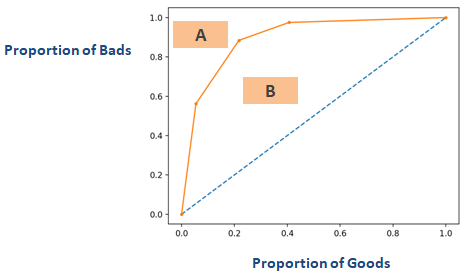
Dacă inversați axa graficului prezentat în secțiunea de mai sus numită „Coeficientul Gini”, veți obține un grafic similar cu cel de mai jos. Aici Gini = B / (A + B). Aria lui A + B este 0,5, deci Gini = B / 0,5, ceea ce se simplifică la Gini = 2*B. AUC = B + 0.5 care se simplifică în continuare la B = AUC – 0,5. Puneți această ecuație în Gini = 2*B
Gini = 2*(AUC – 0.5)
Gini = 2*AUC – 1
.