Kumulativ noggrannhetsprofil (CAP)
Kumulativ noggrannhetsprofil (CAP) för en kreditvärderingsmodell visar procentandelen av alla låntagare (gäldenärer) på x-axeln och procentandelen av de som inte betalar (dåliga kunder) på y-axeln. Inom marknadsföringsanalys kallas denGain Chart. Den kallas också Power Curve inom vissa andra områden.
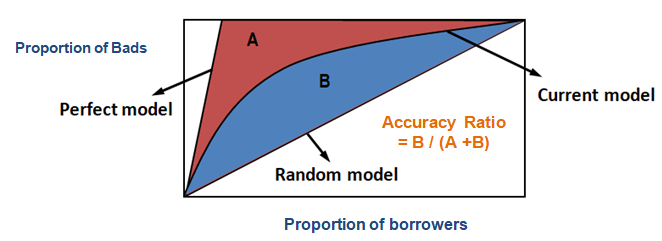
Med hjälp av CAP kan du jämföra kurvan för din nuvarande modell med kurvan för den ”ideala eller perfekta” modellen och kan också jämföra den med kurvan för en slumpmässig modell. Med ”perfekt modell” avses det ideala tillståndet där alla dåliga kunder (önskat resultat) kan fångas upp direkt. Med ”slumpmässig modell” avses ett tillstånd där andelen dåliga kunder är jämnt fördelade. ”Nuvarande modell” avser din modell för sannolikhet för utebliven betalning (eller någon annan modell som du arbetar med). Vi försöker alltid bygga den modell som lutar mot (närmare) kurvan för den perfekta modellen. Vi kan läsa den nuvarande modellen som ”% dåliga kunder som täcks på en given decilnivå”. Exempelvis 89 % av de dåliga kunderna täcks genom att bara välja de 30 % bästa gäldenärerna baserat på modellen.
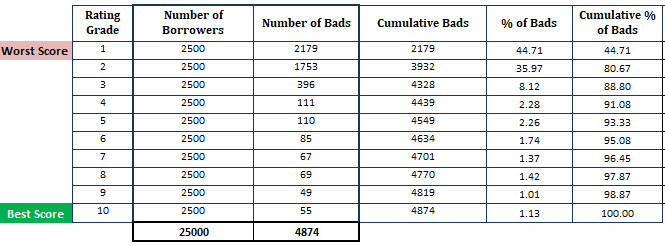
- Sortera den uppskattade sannolikheten för betalningsinställelse i fallande ordning och dela upp den i 10 delar (decil). Det innebär att de mest riskfyllda låntagarna med hög PD ska finnas i den översta decilen och de säkraste låntagarna ska finnas i den nedersta decilen. Att dela upp resultatet i 10 delar är inte en tumregel. Istället kan du använda ratinggrad.
- Beräkna antalet låntagare (observationer) i varje decil
- Beräkna antalet dåliga kunder i varje decil
- Beräkna kumulativt antal dåliga kunder i varje decil
- Beräkna andel dåliga kunder i varje decil
- Beräkna kumulativ andel dåliga kunder i varje decil
Till nu, har vi gjort beräkningar baserade på PD-modellen (kom ihåg att det första steget baseras på de sannolikheter som erhålls från PD-modellen).
Nästa steg: Hur många dåliga kunder bör finnas i varje decil enligt den perfekta modellen?
- I den perfekta modellen bör den första decilen fånga upp alla dåliga kunder eftersom den första decilen hänvisar till den sämsta kreditvärdighetsklassen ELLER låntagare med högst sannolikhet för betalningsinställelse. I vårt fall kan den första decilen inte fånga upp alla dåliga kunder eftersom antalet låntagare i den första decilen är mindre än det totala antalet dåliga kunder.
- Beräkna det kumulativa antalet dåliga kunder i varje decil baserat på perfekt modell
- Beräkna den kumulativa andelen dåliga kunder i varje decil baserat på perfekt modell

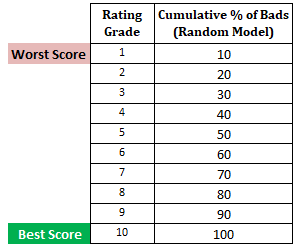
Nästa steg: Beräkna den kumulativa procentandelen dåliga kunder i varje decil baserat på slumpmässig modellI den slumpmässiga modellen bör varje decil utgöra 10 %. När vi beräknar den kumulativa andelen kommer den att vara 10 % i decil 1, 20 % i decil 2 och så vidare till 100 % i decil 10.
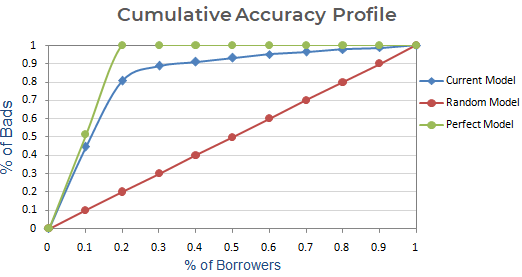
Nästa steg : Skapa en graf med kumulativ andel dåliga kunder baserat på nuvarande, slumpmässig och perfekt modell. På x-axeln visas andelen låntagare (observationer) och y-axeln representerar andelen dåliga kunder.
Noggrannhetskvot
I fallet med CAP (Cumulative Accuracy Profile) är noggrannhetskvoten kvoten mellan arean mellan din nuvarande prediktiva modell och den diagonala linjen och arean mellan den perfekta modellen och den diagonala linjen. Med andra ord är det förhållandet mellan prestandaförbättringen av den nuvarande modellen jämfört med den slumpmässiga modellen och prestandaförbättringen av den perfekta modellen jämfört med den slumpmässiga modellen.
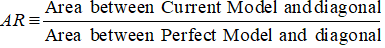
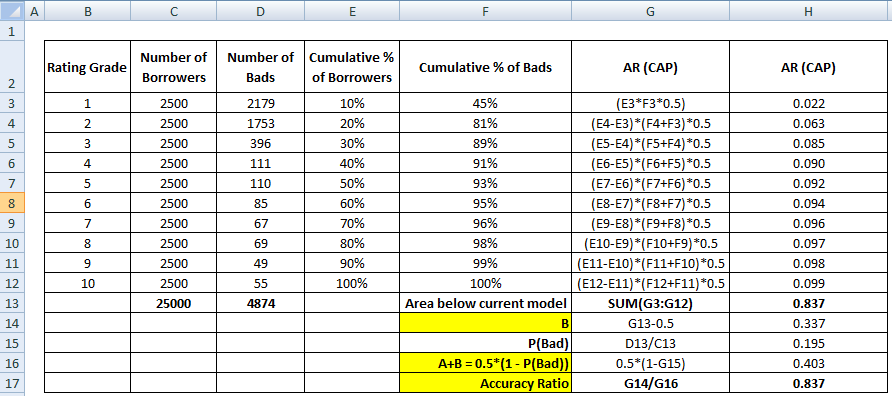
Det första steget är att beräkna arean mellan den nuvarande modellen och den diagonala linjen. Vi kan beräkna arean under den aktuella modellen (inklusive arean under den diagonala linjen) med hjälp av den numeriska integrationsmetoden Trapezoidal Rule Numerical Integration. Arean av en trapets är
( xi+1 – xi ) * ( yi + yi+1 ) * 0,5

( xi+1 – xi ) är bredden på delintervallet och (yi + yi+1)*0,5 är medelhöjden.
I det här fallet hänvisar x till värdena för den kumulativa andelen låntagare på olika decilnivåer och y hänvisar till den kumulativa andelen dåliga kunder på olika decilnivåer. Värdet av x0 och y0 är 0.
När ovanstående steg är slutfört är nästa steg att subtrahera 0,5 från den yta som returneras från föregående steg. Du måste undra över relevansen av 0,5. Det är arean under den diagonala linjen. Vi subtraherar eftersom vi bara behöver arean mellan nuvarande modell och den diagonala linjen (låt oss kalla den B).
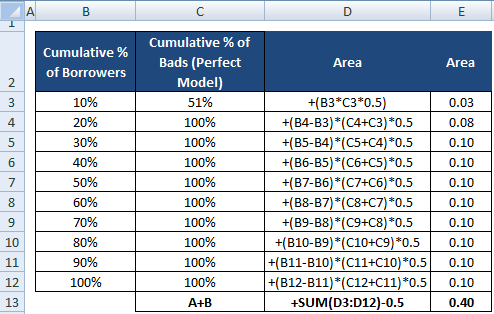
Nu behöver vi nämnaren som är arean mellan den perfekta modellen och den diagonala linjen, A + B. Det motsvarar 0.5*(1 - Prob(Bad)). Se alla beräkningssteg som visas i tabellen nedan –
Nominatorn för AR kan också beräknas på samma sätt som vi utförde beräkningen för täljaren. Det innebär att man beräknar området med hjälp av ”Cumulative % of Borrowers” och ”Cumulative % of Bads (Perfect Model)” och sedan subtraherar 0,5 från det eftersom vi inte behöver ta hänsyn till området under den diagonala linjen.
I R-koden nedan har vi förberett provdata som exempel. Variabelnamnet pred hänvisar till förutsedda sannolikheter. Variabel y hänvisar till beroende variabel (faktisk händelse). Vi behöver bara dessa två variabler för att beräkna Accuracy Ratio.
library(magrittr)library(dplyr)# Sample Data for demonstrationmydata = data.frame(pred = c(0.6,0.1,0.8,0.3,0.5,0.6,0.4,0.3,0.5), y = c(1,0,1,0,1,1,0,1,0))# Sort data in descending order of predicted prob.mydata %% arrange(desc(pred))# Cumulative % Borrowersrandom = 1:length(mydata$pred)/length(mydata$pred)# Cumulative % of Badscumpercentbad = cumsum(mydata$y)/sum(mydata$y)# Calculate ARrandom = c(0,random)cumpercentbad = c(0,cumpercentbad)idx = 2:length(cumpercentbad)testdf=data.frame(cumpercentpop = (random - random), cumpercentbad = (cumpercentbad + cumpercentbad))Area = sum(testdf$cumpercentbad * testdf$cumpercentpop/2)Numerator = Area - 0.5Denominator = 0.5*(1-mean(mydata$y))(AR = Numerator / Denominator)
Ginikoefficient
Ginikoefficienten är mycket lik CAP, men den visar andel (kumulativ) av bra kunder i stället för alla kunder. Den visar i vilken utsträckning modellen har bättre klassificeringsförmåga jämfört med den slumpmässiga modellen. Den kallas också Gini-index. Gini-koefficienten kan anta värden mellan -1 och 1. Negativa värden motsvarar en modell med omvända betydelser av poäng.
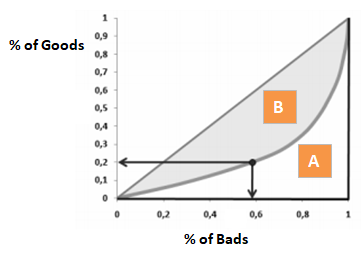
Gini = B / (A+B). Eller Gini = 2B eftersom arean av A + B är 0,5
Se beräkningsstegen för Gini-koefficienten nedan :
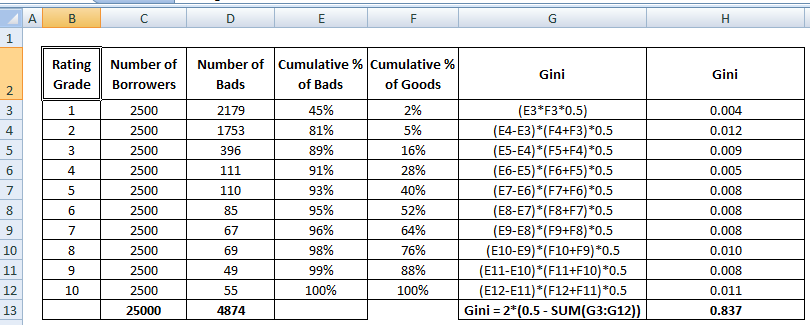
Vid avvisning av x% av de goda kunderna, hur stor andel av de dåliga kunderna avvisar vi tillsammans.
Ginikoefficienten är ett specialfall av Somers D-statistik. Om man har procentuell överensstämmelse och diskordans kan man beräkna Gini-koefficienten.
Gini Coefficient = (Concordance percent - Discordance Percent)Concordance procent avser andelen par där de som missköter sig har en högre förutspådd sannolikhet än de goda kunderna.
Discordance procent avser andelen par där de som missköter sig har en lägre förutspådd sannolikhet än de goda kunderna.
Ett annat sätt att beräkna Gini-koefficienten är att använda concordance och discordance procent (som förklaras ovan). Se R-koden nedan.
ModelPerformance <- function (actuals, predictedScores){ fitted <- data.frame (Actuals=actuals, PredictedScores=predictedScores) # actuals and fitted colnames(fitted) <- c('Actuals','PredictedScores') # rename columns ones <- fitted # Subset ones zeros <- fitted # Subsetzeros totalPairs <- nrow (ones) * nrow (zeros) # calculate total number of pairs to check # A pair is concordant if 1 (event) has a higher predicted probability than 0 conc <- sum (c(vapply(ones$PredictedScores, function(x) {((x > zeros$PredictedScores))}, FUN.VALUE=logical(nrow(zeros)))), na.rm=T) # A pair is disconcordant if 1 (event) has a lower predicted probability than 0 disc <- sum(c(vapply(ones$PredictedScores, function(x) {((x < zeros$PredictedScores))}, FUN.VALUE = logical(nrow(zeros)))), na.rm = T) # Calculate concordance, discordance, ties and AUC concordance <- conc/totalPairs discordance <- disc/totalPairs tiesPercent <- (1-concordance-discordance) Gini = (conc-disc)/totalPairs AUC = concordance + 0.5*tiesPercent return(list("Concordance"=concordance, "Discordance"=discordance, "Tied"=tiesPercent, "Gini"= Gini,"AUC"=AUC))}ModelPerformance(mydata$y, mydata$pred)
Är Ginikoefficienten och noggrannhetskvoten likvärdiga?
Ja, de är alltid likvärdiga. Därför kallas Ginikoefficienten ibland Accuracy Ratio (AR).
Ja, jag vet att axlarna i Gini och AR är olika. Frågan är hur de fortfarande är lika. Om du löser ekvationen skulle du finna att Area B i Gini-koefficienten är densamma som Area B / Prob(Good) i Accuracy Ratio (vilket motsvarar (1/2)*AR ). Genom att multiplicera båda sidorna med 2 får man Gini = 2*B och AR = Area B / (Area A + B)
Area under ROC-kurvan (AUC)
AUC eller ROC-kurvan visar andelen sant positiva resultat (en icke-fuskare klassificeras korrekt som en icke-fuskare) jämfört med andelen falskt positiva resultat (en icke-fuskare klassificeras felaktigt som en icke-fuskare).
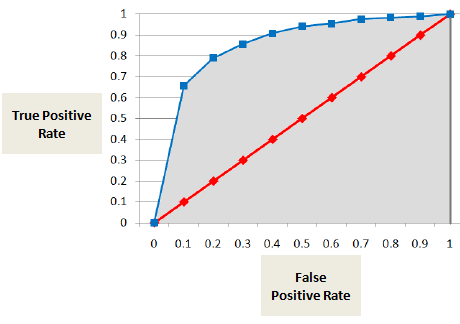
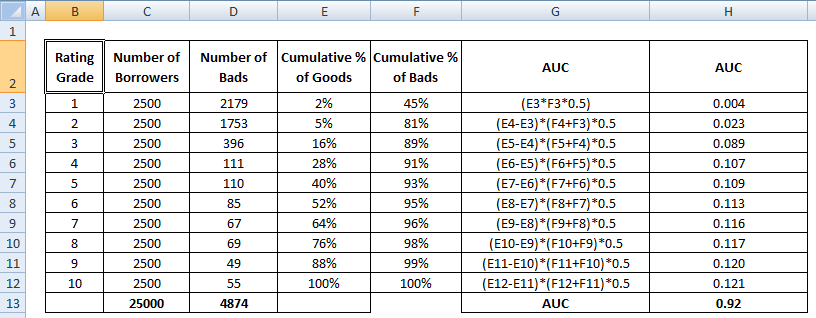
AUC-poäng är summan av alla individuella värden som beräknats på betygsnivå eller decilnivå.
4 Metoder för att beräkna AUC Matematiskt
Samband mellan AUC och Ginikoefficienten
Gini = 2*AUC – 1.
Du undrar säkert hur de hänger ihop.
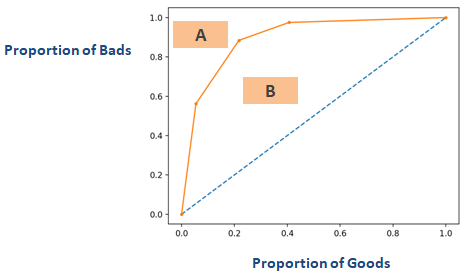
Om du vänder på axeln i diagrammet som visas i avsnittet ovan med namnet ”Ginikoefficient” får du ett diagram som liknar nedanstående. Här Gini = B / (A + B). Arean av A + B är 0,5 så Gini = B / 0,5 vilket förenklas till Gini = 2*B. AUC = B + 0.5 vilket ytterligare förenklas till B = AUC – 0,5. Sätt in denna ekvation i Gini = 2*B
Gini = 2*(AUC – 0,5)
Gini = 2*AUC – 1
.